wpandas_profiling的作用:类似于pandas的describe()和info()函数,用来查看数据的整体情况,比如平均值、标准差之类,即探索性数据分析-EDA,可以快速的浏览数据的大致情况。
1.安装:我用的是jupyter_notebook,直接输入下面一行代码即可:(可能会提示部分库版本不够,需要升级,根据提示升级即可,升级方法也很简单,直接pip install+需要升级的包名)
pip install pandas-profiling2.数据集:安装完后就可以使用了,用的也是大家平时比较常用的kaggle的数据集:泰坦尼克号数据;可点击下载,下文演示用的主要为train.csv里面的数据
![]()
![]()
![]()
3.进入正题,几行代码快速生成:
import pandas as pd
from pandas_profiling import ProfileReport
#导入数据
df=pd.read_csv(r"C:/Users/86134/Desktop/python/titanic_泰坦尼克数据集/train.csv")
profile =ProfileReport(df,title ="titanic Dataset ",explorative=True) #title可以自己取
profile.to_file("report.html") #file的名字也是可以自己取的,这个分析报告导出是html格式的4.看看3.0版本的pandas_profiling有哪些内容吧:

左上角是自己命名的文件名字:titanic Dataset,右上角分别是这个数据分析的六大部分:overview、variables、interactions、Correlations、Mising values、Sample.
(1)Overview:
这部分有三个部分内容、overview、warmings、Reproduction.
overview:首先overview是这个数据集的概述,包含着变量的个数、样本数量、缺失总量、缺失比例,重复的列,重复列比例,文件的大小,以及变量的类型。
Warnings: 汇总了变量之间的一些相关信息,包括High cardinality(不一样的值较多)、high correlation(高相关性)、Missing(缺失值)、uniform(分布均匀)、unique(唯一性)、zeros(有0值)

reproduction:该部分回顾的是生成报告的一些参数,包括开始和结束时间、生成报告时长,包的版本号、下载配置等信息。

(2)Variables
该部分主要对各变量的情况进行分析:




每一项会标注该变量的类型,以及给出相应的提示,比如说存在缺失值,和某个值存在高相关性等等。同时展示概述内容,包括该变量有多少不同的取值,每个取值的占比,缺失值/缺失值占比,右边会给出每个取值的个数。若对某个变量感兴趣,可点击右下角的toggle details,切换成详细模式:

以survived字段举例,详细模式中包含overview、categories、words、characters四个页面,首先overview中包括length、Characters and Unicode、unique、sample四部分信息:
length描述了name这个字段的长度信息:最长度、中位数、平均值及最小值
Characters and Unicode:字符总数、字符类型,种类、字体、分区
unique:唯一值个数/比例
sample:给出了前五个例子,类似于head()的用法;
categories:
 words:
words:
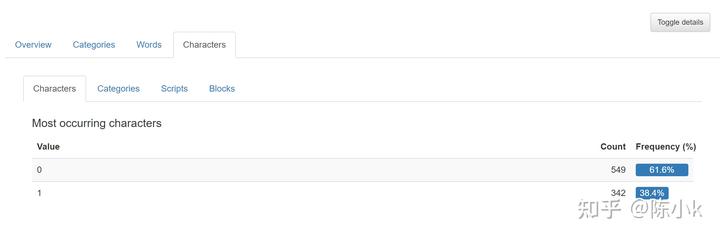
 Characters:
Characters:
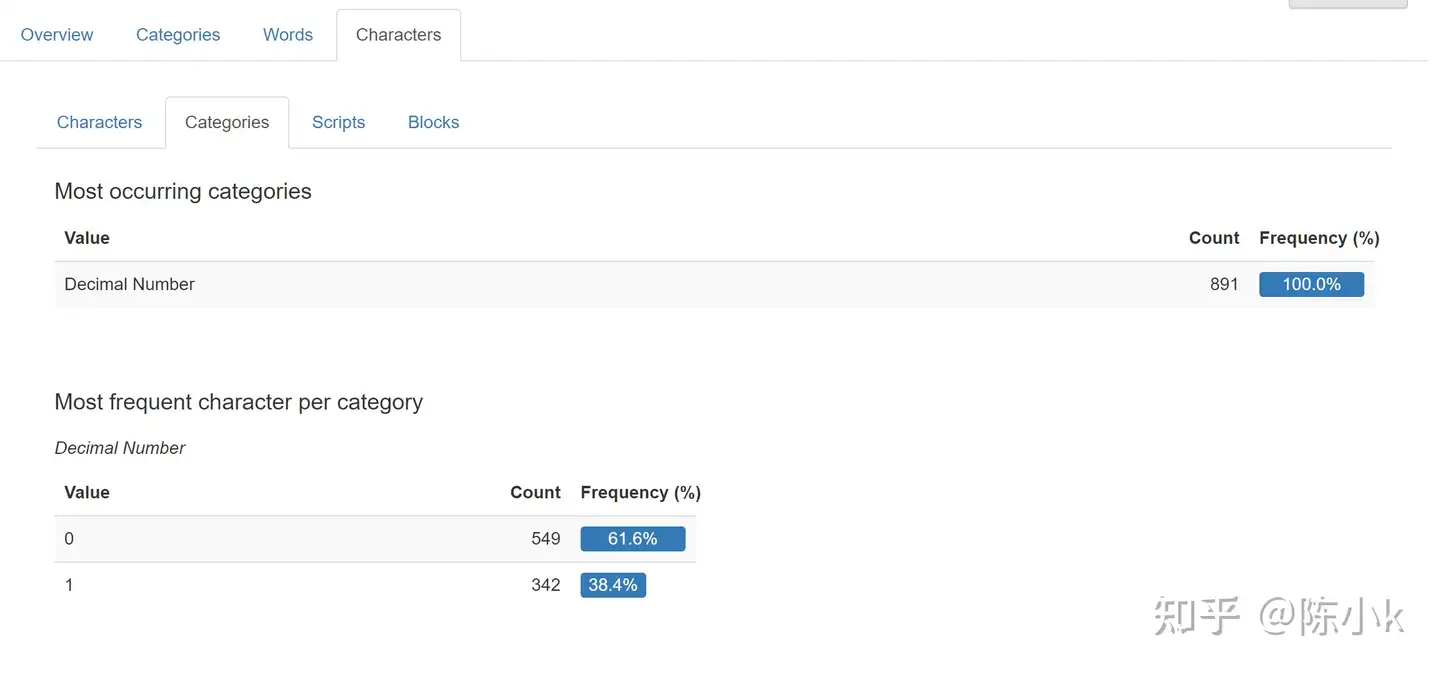
 character里面又继续细分又characters、Categories、Scripts和blocks 4个部分:
character里面又继续细分又characters、Categories、Scripts和blocks 4个部分:
Categories如下,survive只有数值类型的数据,分为为0和1,0的占比为61.6%
scripts:字体

blocks:编码方式
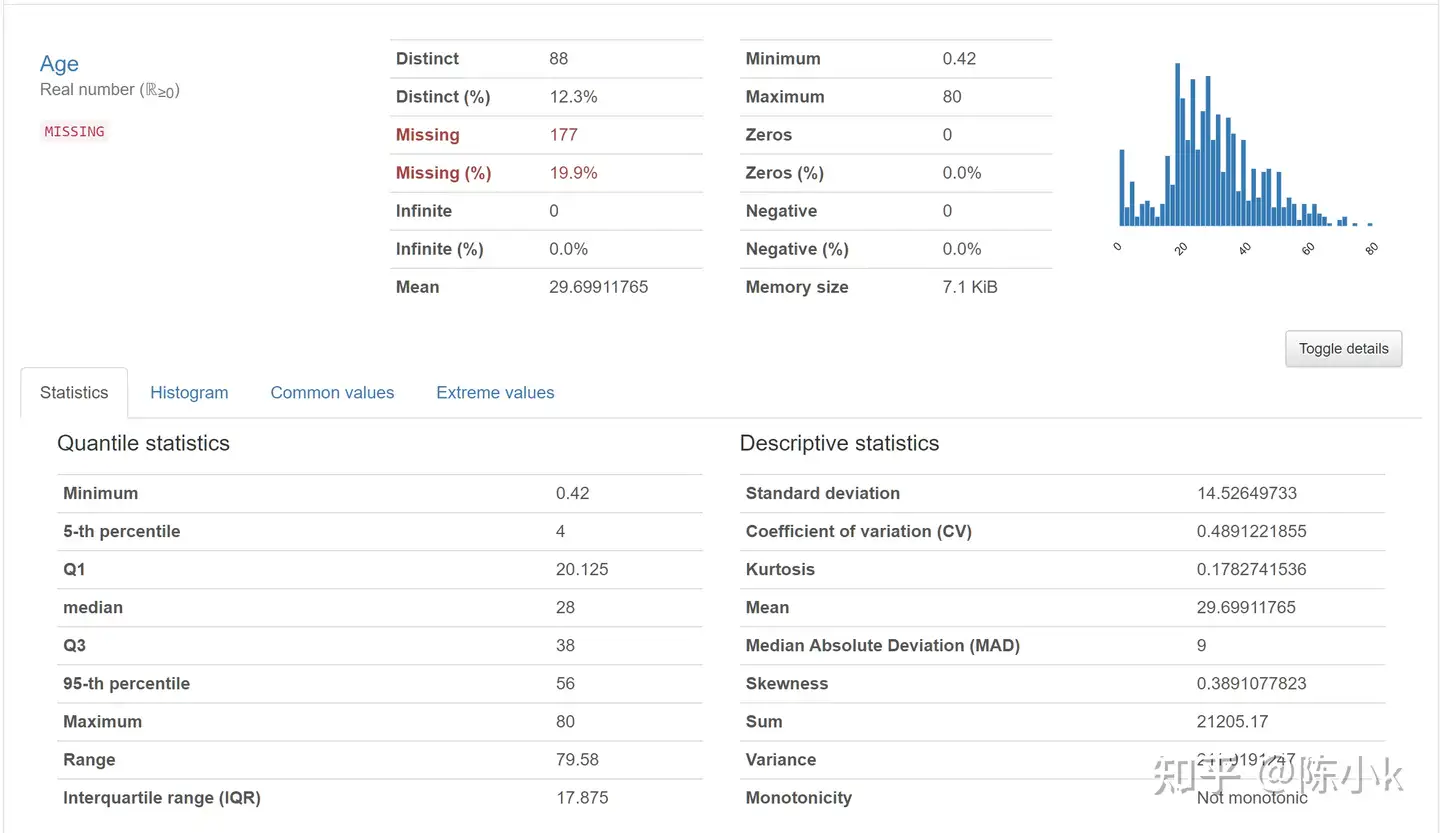
除了Categorical类型以外,还会有Real number (ℝ≥0)(比如age):该部分会有一些统计量,如极大值,极小值,0值,平均值,分位数,中位数等等。具体不赘述了,上图:有兴趣的同学可以自己跑跑。details下变成了statistics,histogram,common values和extreme values四部分:
statistics:
histogram:

common values: 展示值的的分布,以及缺失值的数量及比例

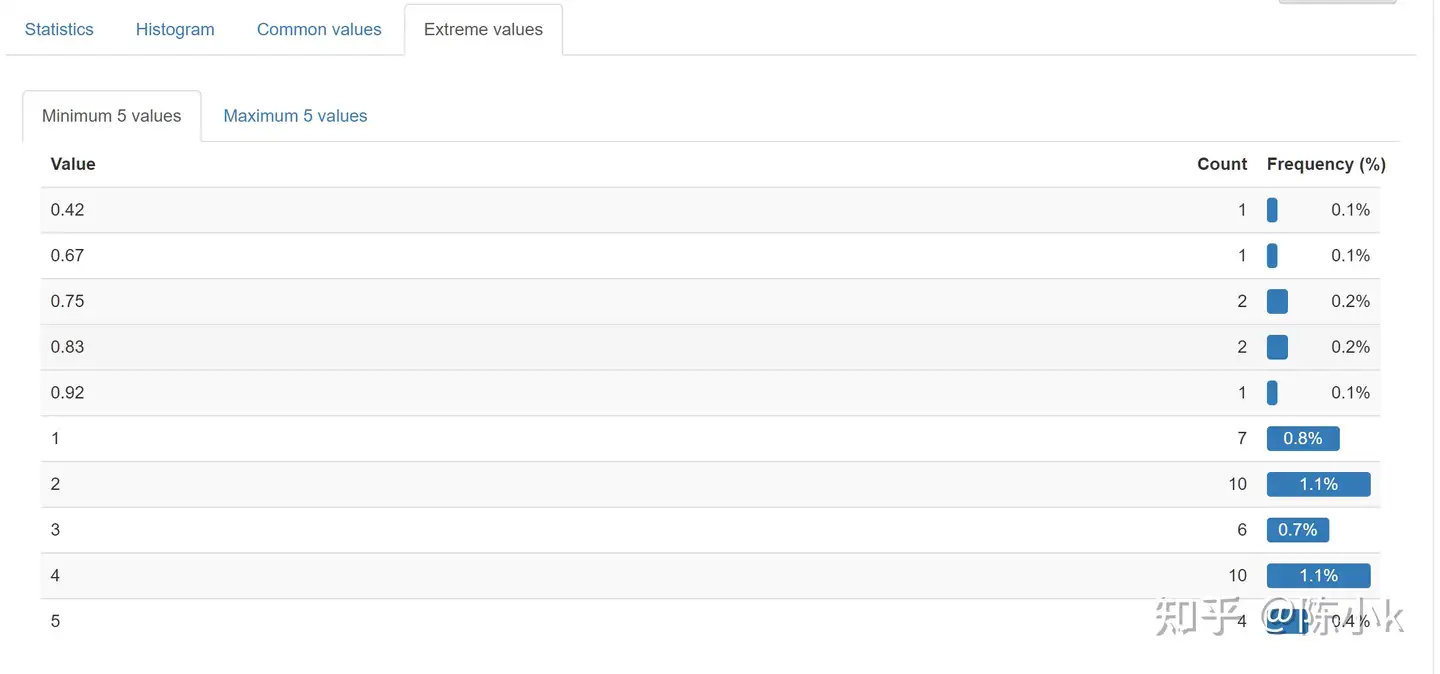
Extreme values:该部分有极大值和极小值

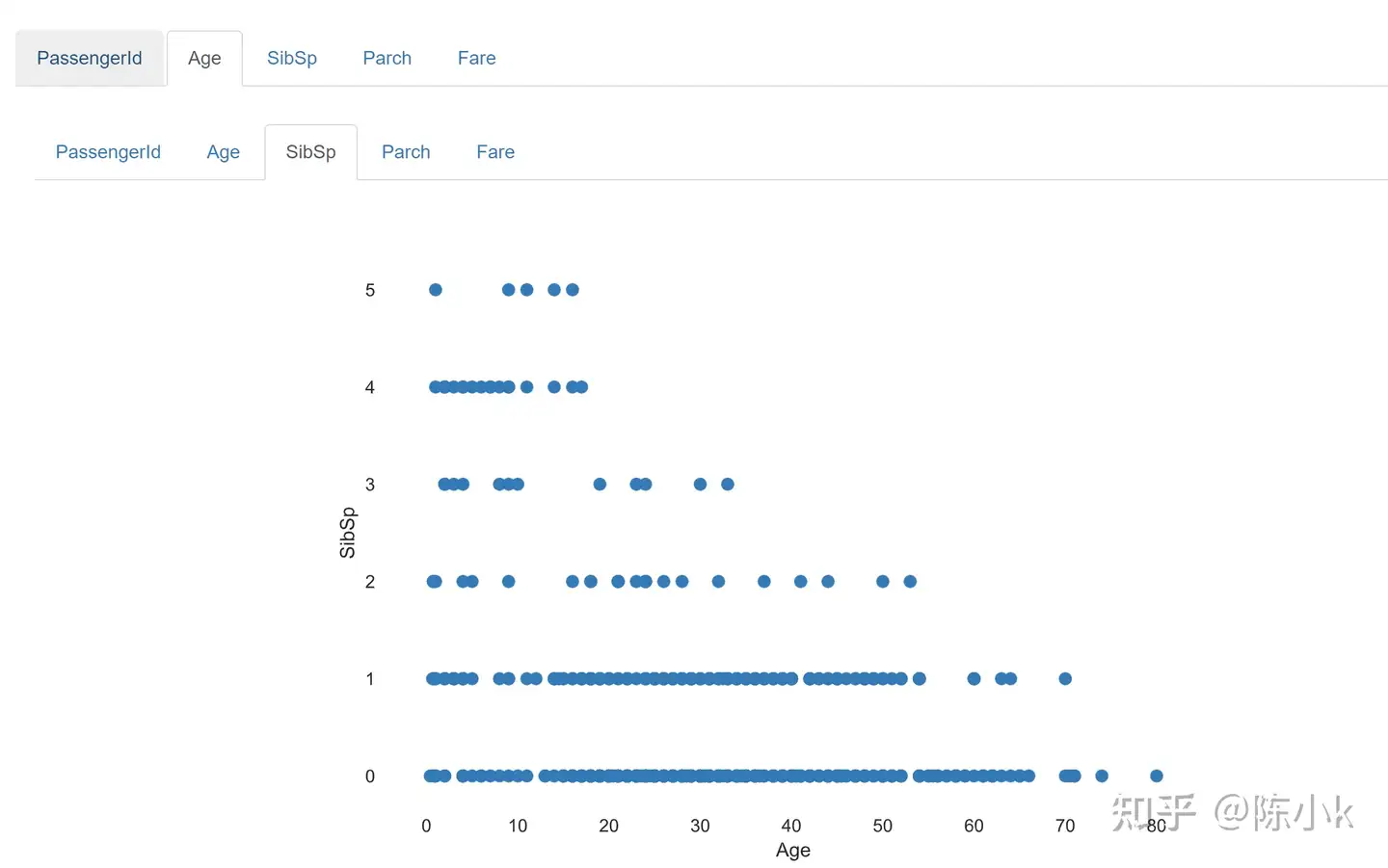
讲完变量就来到第三部分,Interactions:这部分主要展现两两变量间的关系:如下图展示年龄和兄弟姐妹间的相关性
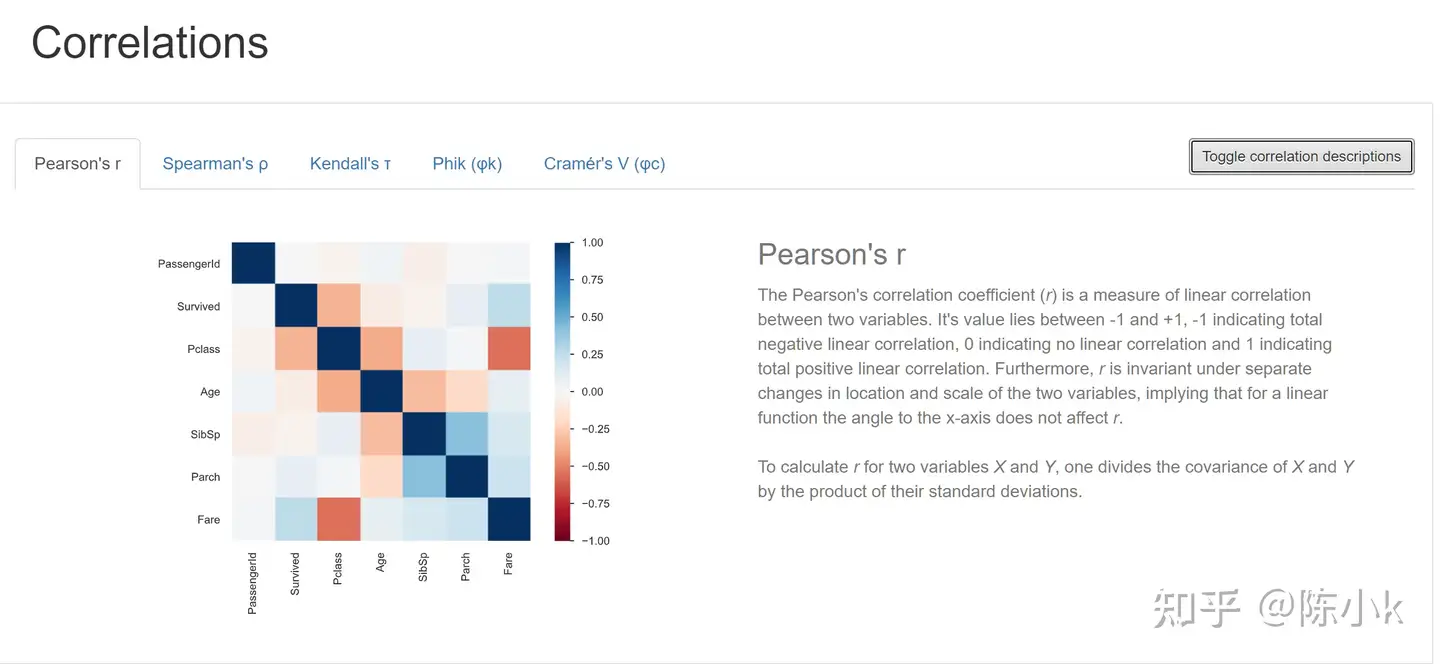
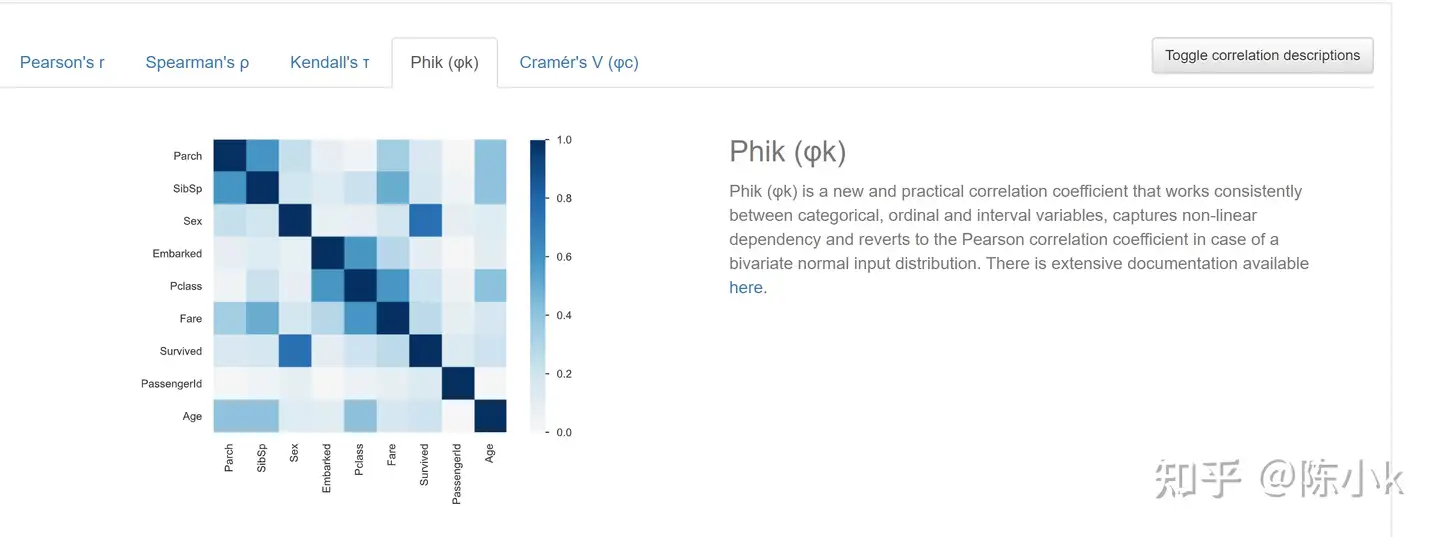
接着是Correlations:通过五种方法来展现相关性,包括pearson’s,Spearman’s,Kendall’s ,Phik,Cramér’s:



Missing values:




最后是sample的部分了,类似于head()和tail(),给出了数据的前部和后部供大家参考:

总体来说是非常直观的EDA,也非常简单,感兴趣的童鞋可以安装包试一下哦~~~