著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:不求东西
链接:https://www.zhihu.com/question/32246256/answer/55496955
来源:知乎
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:不求东西
链接:https://www.zhihu.com/question/32246256/answer/55496955
来源:知乎
一個非洲酋長到倫敦訪問,一群記者在機場截住了他。
早上好,酋長先生”, 其中一人問道:你的路途舒適嗎?
酋長發出了一連串刺耳的聲音哄、哼、啊、吱、嘶嘶,
然后用純正的英語說 道 :是的,非常地舒適。
那麼!您准備在這里待多久?
他發出了同樣的一連串噪音,
然後答:大約三星期,我想。
酋長,告訴我,你是在哪學的這樣流利的英語?迷惑不解的記者問。
又是一陣哄、吭、啊、吱、嘶嘶聲,
酋長說:從短波收音機裡。
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:郑昆
链接:https://www.zhihu.com/question/32246256/answer/55251597
来源:知乎
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:郑昆
链接:https://www.zhihu.com/question/32246256/answer/55251597
来源:知乎
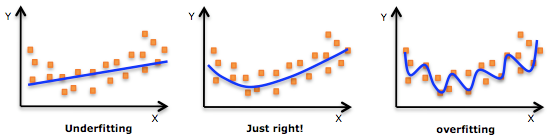
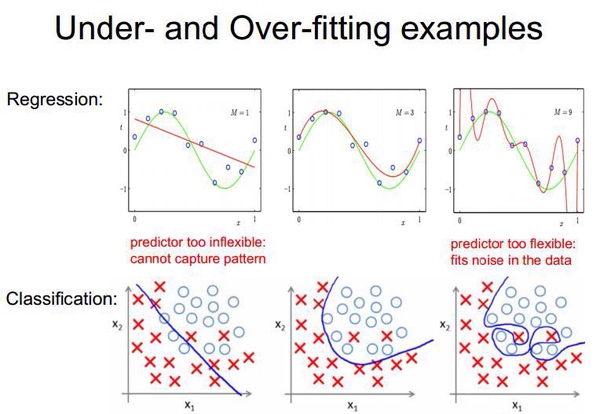
其实不完全是噪声和假规律会造成过拟合。
(1)打个形象的比方,给一群天鹅让机器来学习天鹅的特征,经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的弯曲的,天鹅的脖子是长长的有点曲度,天鹅的整个体型像一个“2”且略大于鸭子.这时候你的机器已经基本能区别天鹅和其他动物了。
(2)然后,很不巧你的天鹅全是白色的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅.
(3)好,来分析一下上面这个例子:(1)中的规律都是对的,所有的天鹅都有的特征,是全局特征;然而,(2)中的规律:天鹅的羽毛是白的.这实际上并不是所有天鹅都有的特征,只是局部样本的特征。机器在学习全局特征的同时,又学习了局部特征,这才导致了不能识别黑天鹅的情况.
————————————————–理论总结分割线—————————————-
(1)对于机器来说,在使用学习算法学习数据的特征的时候,样本数据的特征可以分为局部特征和全局特征,全局特征就是任何你想学习的那个概念所对应的数据都具备的特征,而局部特征则是你用来训练机器的样本里头的数据专有的特征.
(2)在学习算法的作用下,机器在学习过程中是无法区别局部特征和全局特征的,于是机器在完成学习后,除了学习到了数据的全局特征,也可能习得一部分局部特征,而习得的局部特征比重越多,那么新样本中不具有这些局部特征但具有所有全局特征的样本也越多,于是机器无法正确识别符合概念定义的“正确”样本的几率也会上升,也就是所谓的“泛化性”变差,这是过拟合会造成的最大问题.
(3)所谓过拟合,就是指把学习进行的太彻底,把样本数据的所有特征几乎都习得了,于是机器学到了过多的局部特征,过多的由于噪声带来的假特征,造成模型的“泛化性”和识别正确率几乎达到谷点,于是你用你的机器识别新的样本的时候会发现就没几个是正确识别的.
(4)解决过拟合的方法,其基本原理就是限制机器的学习,使机器学习特征时学得不那么彻底,因此这样就可以降低机器学到局部特征和错误特征的几率,使得识别正确率得到优化.
(5)从上面的分析可以看出,要防止过拟合,训练数据的选取也是很关键的,良好的训练数据本身的局部特征应尽可能少,噪声也尽可能小.
(1)打个形象的比方,给一群天鹅让机器来学习天鹅的特征,经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的弯曲的,天鹅的脖子是长长的有点曲度,天鹅的整个体型像一个“2”且略大于鸭子.这时候你的机器已经基本能区别天鹅和其他动物了。
(2)然后,很不巧你的天鹅全是白色的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅.
(3)好,来分析一下上面这个例子:(1)中的规律都是对的,所有的天鹅都有的特征,是全局特征;然而,(2)中的规律:天鹅的羽毛是白的.这实际上并不是所有天鹅都有的特征,只是局部样本的特征。机器在学习全局特征的同时,又学习了局部特征,这才导致了不能识别黑天鹅的情况.
————————————————–理论总结分割线—————————————-
(1)对于机器来说,在使用学习算法学习数据的特征的时候,样本数据的特征可以分为局部特征和全局特征,全局特征就是任何你想学习的那个概念所对应的数据都具备的特征,而局部特征则是你用来训练机器的样本里头的数据专有的特征.
(2)在学习算法的作用下,机器在学习过程中是无法区别局部特征和全局特征的,于是机器在完成学习后,除了学习到了数据的全局特征,也可能习得一部分局部特征,而习得的局部特征比重越多,那么新样本中不具有这些局部特征但具有所有全局特征的样本也越多,于是机器无法正确识别符合概念定义的“正确”样本的几率也会上升,也就是所谓的“泛化性”变差,这是过拟合会造成的最大问题.
(3)所谓过拟合,就是指把学习进行的太彻底,把样本数据的所有特征几乎都习得了,于是机器学到了过多的局部特征,过多的由于噪声带来的假特征,造成模型的“泛化性”和识别正确率几乎达到谷点,于是你用你的机器识别新的样本的时候会发现就没几个是正确识别的.
(4)解决过拟合的方法,其基本原理就是限制机器的学习,使机器学习特征时学得不那么彻底,因此这样就可以降低机器学到局部特征和错误特征的几率,使得识别正确率得到优化.
(5)从上面的分析可以看出,要防止过拟合,训练数据的选取也是很关键的,良好的训练数据本身的局部特征应尽可能少,噪声也尽可能小.
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:十方
链接:https://www.zhihu.com/question/32246256/answer/55320482
来源:知乎
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:十方
链接:https://www.zhihu.com/question/32246256/answer/55320482
来源:知乎
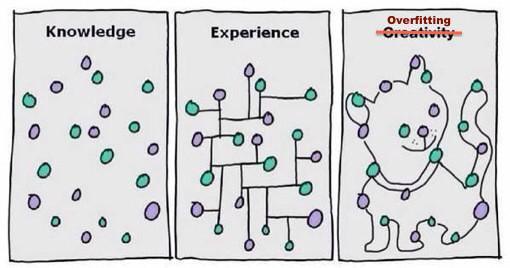
过拟合有两种原因:
- 训练集和测试机特征分布不一致(白天鹅黑天鹅)
- 或者模型太过复杂(记住了每道题)而样本量不足
解决过拟合也从这两方面下手,收集多样化的样本,简化模型,交叉检验。
最后配个图,看图最清楚了。