IBM SPSS 软件家族预测分析模型的商业应用初探,第 4 部分: 应用 Modeler 支持向量机模型评估银行客户信用
银行典型案例
商业银行个人信用评估就是根据个人信息和借贷记录等历史数据,判断个人信用,它是保证信贷安全的重要一环。但是商业银行用于信用评估的数据往往具有特性不稳定,历史样本容量较小,指标较多,呈明显的非正态分布。这些特点导致很难利用一般的统计技术进行有效的评估。支持向量机模型 ( 简称 SVM) 能够很好的处理此类数据,进行有效的信用评估。本文介绍了 SVM 的基本概念以及 Modeler 中使用 SVM 进行信用评估的基本步骤和方法,并对结果进行分析和应用。
支持向量机模型简介
支持向量机 (Support Vector Machine, 简称 SVM) 是一项功能强大的分类和回归技术,可最大化模型的预测准确度。与其他常用模型不同,SVM 一个优势就是能很好的处理小样本,高维数,非正态的数据。
SVM 的工作原理是将原始数据通过变换映射到高维特征空间,这样即使数据不是线性可分,也可以对该数据点进行分类。之后,使用变换后的新数据的进行预测分类。例如,图 1 中的数据点落到了两个不同的类别中,可以用一条曲线分隔这两个类别。对数据使用某种数学函数变换后,可以用超平面定义这两个类别之间的边界。
图 1. 数据变换后线性可分示意图
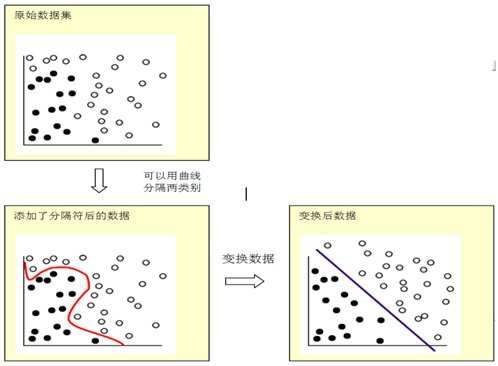
用于变换的数学函数称为核函数。IBM SPSS Modeler 中的 SVM 支持下列核函数类型:
- 线性
- 多项式
- 径向基函数 (RBF)
- Sigmoid
如果数据的线性分隔比较简单,则建议使用线性核函数。在其他情况下,应当使用其他核函数。在所有情况下,最好尝试使用不同的核函数,才能从中找出最佳模型,因为每一个函数均使用不同的算法和参数。
使用 IBM SPSS Modeler 支持向量机模型评估客户信用
IBM SPSS Modeler 中的 SVM 提供了可视化的操作方法,具有界面友好,操作方便的特点。此节,介绍如何使用 IBM SPSS Modeler SVM 评估客户信用。操作步骤分为:
- 创建基本流(Modeler Stream),建立模型;
- 测试模型,分析结果;
- 用不同的核函数建模,比较并选择合适的模型;
- 运用选定的模型来评估客户信用。
我们使用 UCI Machine Learning Repository 上公开的商业银行客户信用记录作为数据集进行演示。该数据集由 1000 条个人信用记录组成,每条记录均包含一组个人信息值,其中包括对客户信用的评估结果。1000 条记录保存在 CreditData.csv 文件中,从 1000 条记录中抽出一部分用于演示用选定的模型评估客户信用,将这部分数据保存到 CreditData4Estimate.csv 文件中。
创建基本流(Modeler Stream),建立模型
图 2. 基本流建模图
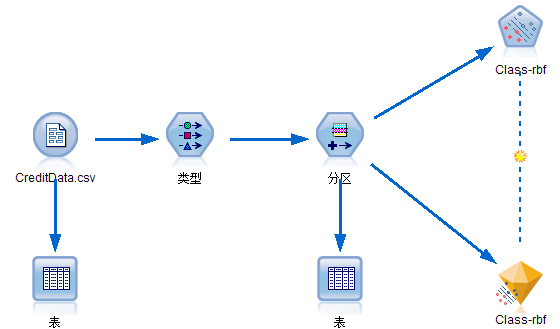
基本流如图 2 所示,创建步骤如下
1) 添加源数据—选择合适的数据
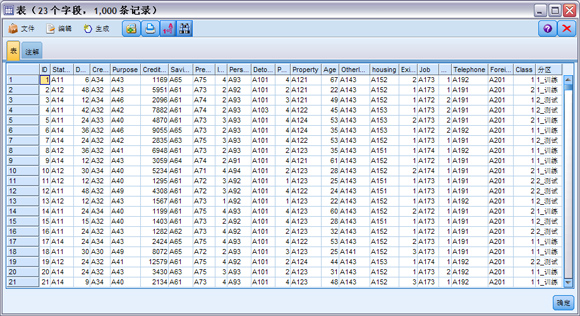
创建新流,命名为 SVM.str。从“源”选项卡中添加一个“可变文件”节点到 SVM.str,从“输出”选项卡中添加一个“表”节点到流,并将“表”节点连接到“可变文件”节点。打开“可变文件”节点,导入客户信用数据 CreditData.csv。运行“表”节点,显示源文件中数据,如图 3 所示。数据有 22 个字段,1000 条记录。ID 字段为客户标志符。每个客户的信息包含在从 StatusChkAccount到 Foreigner的字段中。Class字段表示信用评级,取值为良 ( 值 =1) 或者差 ( 值 =2)。
图 3. 源数据图

2) 设置类型—选择用作预测的变量和目标变量
从“字段选项”选项卡中添加一个“类型”节点到 SVM.str, 并将它连接到“可变文件”节点之后,打开“类型”节点,并单击 [ 读取值 ] 按钮。获得数据集描述,如图 4 所示。
图 4. 源数据类型描述图
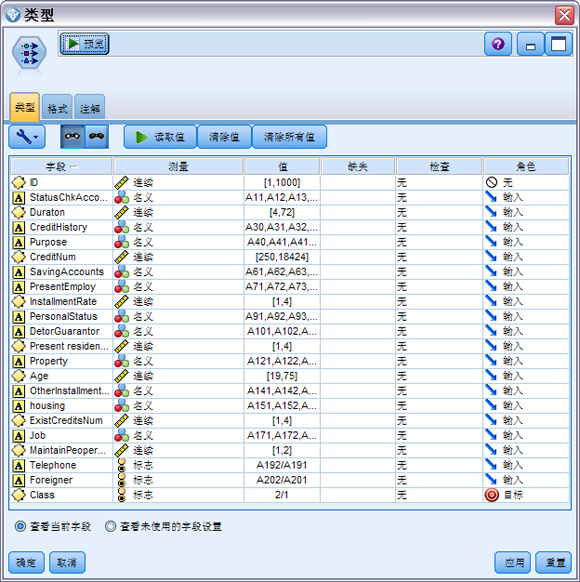
本模型,希望预测 Class的值 ( 此字段只有 2 个值,即良 (=1) 还是差 (=2))。在“类型”设置界面中,单击 Class字段的“测量”列,将其改为“标志”,将 Class的角色设置为 “目标”;ID字段作为个人标识符,不会对建模和预测产生影响,不会用作预测变量或模型的目标,将其角色设置为“无”; 其他字段作为特征字段用作预测变量,因此将其角色设置为 “输入”。
3) 添加分区—选择建模的数据和测试模型的数据
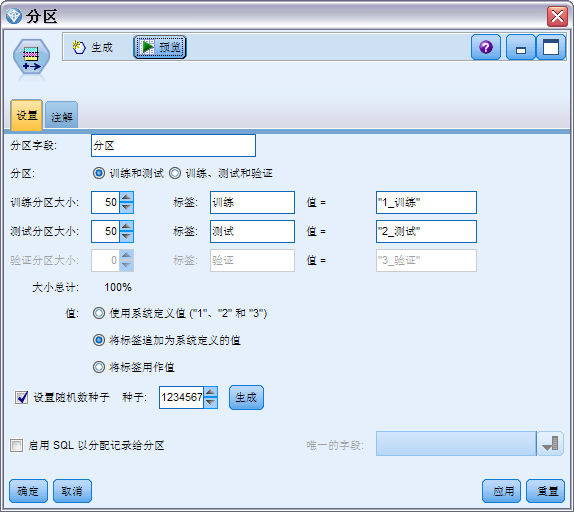
为了建立模型 ( 即训练模型 ),同时测试模型,需要把数据集 CreditData.csv 分为两部分,一部分用于建立模型,另一部分用于测试新建模型。分区节点通过在源数据表中添加一个字段,根据字段的不同取值,将数据分区。“分区”节点最多可以将数据分为三部分,分别用于训练、测试和验证。
从“字段选项”选项卡中添加“分区”节点到流,将其连接到“类型”节点,打开“分区”节点,使用默认设置。默认分为“训练”和“测试”两个分区,大小分别 50%。选择“设置随机种子数”表示分区是随机分区的。
图 5. 分区节点图
添加“表”节点并连接到“分区”节点之后。运行“表”节点,如图 6 所示,“分区”字段被加入到表中。
图 6. 添加分区字段的数据图
4) 添加“建模”节点—建模
从“建模”选项卡中添加“SVM”节点,并连接到“分区”节点之后。双击“SVM”节点,设置属性。
“字段”选项卡默认选中“使用类型节点设置”。
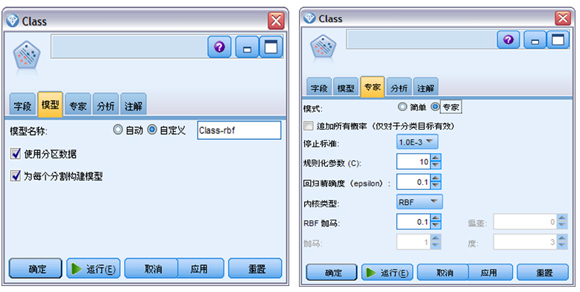
在“模型”选项卡中,如图 7 左所示,选中“自定义”选项,在相邻的文本字段中键入 class-rbf 作为“模型名称”;默认选中“使用分区数据”和“为每个分割构建模型”,流中没有添加“分割”节点,这个选项没有实际作用,关于其功能这里不介绍,有兴趣的读者可以参考帮助文档。
在专家选项卡中,如图 7 右所示,将“模式”设为“专家”以获得可靠性,“内核类型”(即核函数)默认设为 RBF,其他选项使用默认值,这些选项是建模参数,这里不介绍,有兴趣的读者可以参考帮助文档。在“简单”模式下所有选项均为不可设置。
图 7. 模型设置图
在“分析”选项卡上,选中“计算变量重要性”复选框,其他两个选项“计算原始的趋向得分”和“计算调整倾向得分”默认不选中,关于这两个选项功能,这里不介绍,有兴趣的读者可以参考帮助文档。
“注解”选项卡不作额外设置。
单击运行。运行成功表示建模完成,创建模型块被添加到流中。至此,流基本建立完毕,如上面图 2 所示。
测试模型,分析结果
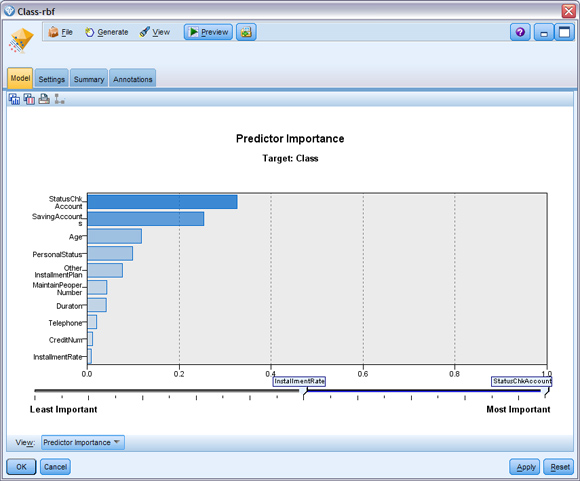
双击建模生成的模型块 class-rbf。如图 8 所示,在“模型”选项卡上,预测变量重要性图显示了不同变量对预测的影响程度,从上到下预测变量的重要程度依次降低,其中 StatusChkAccount和 SavingAccounts的对预测的影响度最大。“设置”选项卡指定在查看结果时显示的附加字段。“汇总”选项卡显示了分析 ( 包含记录数,分析准确性 )、字段、构建设置、训练汇总等信息。这两个选项卡的详细功能,本文不介绍,请参考帮助文档。
图 8. 模型图
模型块 class-rbf 之后添加“表”节点,运行表节点,使用创建的 class-rbf 模型对源数据中数据进行测试,获得图 9 所示结果。
图 9. 训练评估结果图
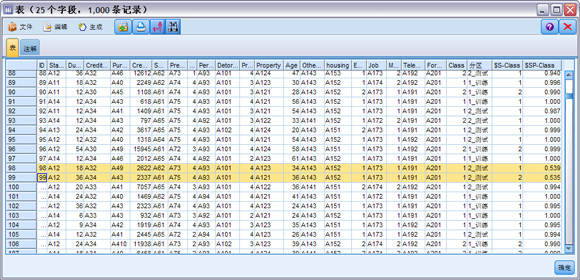
图 9 的结果中,class-rbf 模型创建了两个新字段。向右滚动表输出可看到这两个字段:
表 1.带表头、所有列左对齐的样式
| 新字段名 | 描述 |
|---|---|
| $S-Class | 由模型预测的 Class 值。 |
| $SP-Class | 此预测值的倾向得分(即此预测值正确的可能性,其值介于 0.0 到 1.0 之间)。表示预测值的准确程度,值越高,越说明预测值准确性越高 |
查看上表,看到大多数记录的倾向得分($SP-Class 列)都相当高,即预测的准确度相当高。但是也存在一些明显的例外情况 , 例如图 9 位于第 98 和 99 行的记录,其倾向得分为 0.539 和 0.535。比较这两行的 Class 和 $S-Class,可以看到此模型对这两行记录做出了不正确的预测。因此,在实际使用模型预测时,选择相信倾向得分大于预设值的预测结果。
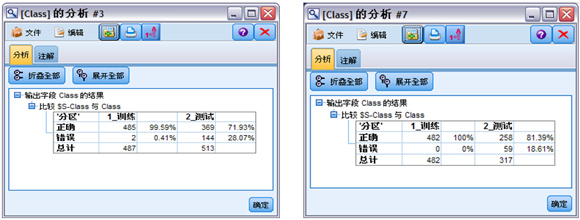
为了统计表中的预测信息,添加“分析”节点并连接到 class-rbf 模型块,运行“分析”节点,获得预测汇总结果 , 如图 10 左所示。根据汇总结果,class-rbf 模型对于“1_ 训练”分区,预测正确率是 99.59%;对于“2_ 测试”分区,预测正确率是 71.93%。
如果选择相信倾向得分大于 0.95 的预测结果,那么预测正确率更高。添加“选择”节点,将其连接至 class-rbf 模型块之后,再将“分析”节点连接至“选择”节点之后 ( 在警告对话框上选择替换 ),在“选择”节点中设置只包含 $SP-Class>=0.95 的记录。再运行“分析”节点,得到图 10 右所示结果。可以看到 class-rbf 模型对于“2_ 测试”部分的预测正确率达到 81.39%
图 10. 模型测试结果图
使用不同的核函数,选择最合适模型
为了比较不同的核函数创建的模型,添加第二个“SVM”建模节点并连接到“分区”节点之后,打开新“SVM”节点,在“模型”选项卡上选择“自定义”并将 class-poly 作为模型名称;在“专家”选项卡上,将模式设置为专家;将内核类型设置为多项式并单击运行,class-poly 模型块被成功创建。将 class-poly 模型块连接到 class-rbf 模型块之后(在警告对话框上选择替换),将 class-poly 模型连接到“分析”节点 ( 在警告对话框上选择替换 ), 在 class-poly 模型块之后添“表”节点。最终建立的流如图 11 所示。我们还可以看到 class-rbf 模型块和 class-poly 模型块被添加到屏幕右上角的“模型”选项板。
图 11. 多核函数建模图
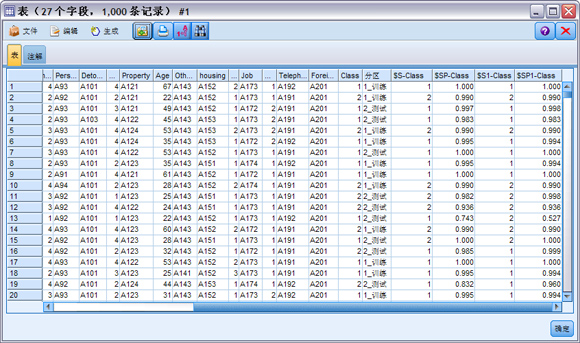
运行连接到 class-poly 模型的表节点,如图 12 所示 , 为 class-poly 模型生成的预测值和倾向得分字段分别命名为 $S1-Class 和 $SP1-Class。可以对比对每条记录两个模型预测结果。
图 12. 两模型评估结果图
为了比较两个模型各自的预测准确度,运行分析节点,获得图 13 所示结果。
图 13. 两模型评估分析图
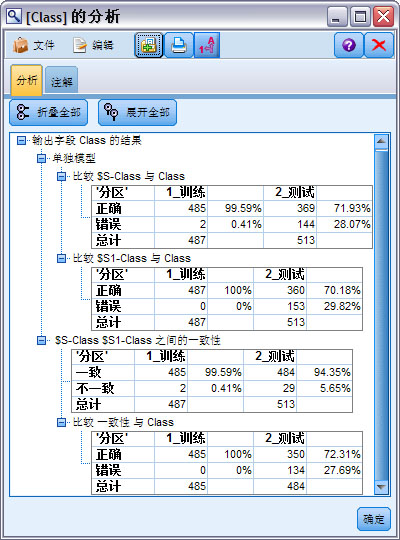
上图中,“单独模型”下面的“比较 $S-Class 与 Class”表示模型 Class-rbf 的预测结果,它与上面图 10 左的结果是一致的。“比较 $S1-Class 与 Class”表示 Class-poly 模型预测结果,该模型对于 487 条“1_ 训练”记录,全部预测正确;对于 513 条“2_ 测试”记录,有 360 条记录预测正确,正确率为 70.18%.
“$S-Class$S1-Class 之间的一致性”表示对所有的记录,两个模型预测结果相同的记录的统计信息。对于“1_ 训练”分区,两模型对于 485 ( 占训练记录总数 99.59%) 条记录的预测结果是相同的,对于“2_ 测试”分区,对 484 ( 占测试记录总数 94.35%) 条记录预测结果是相同的。“比较一致性与 class”表示两个模型预测结果相同的记录中,分别被正确预测和错误预测的记录数。从图 13 中可见,对“1_ 训练”分区,两模型预测结果相同的 485 条记录中,485 条记录被正确预测,0 条被错误预测;对“2_ 测试”分区,两模型预测结果相同的 484 条记录中,有 350 条记录被正确预测,134 条被错误预测,预测正确率为 72.31%。
可以看到,对于“1_ 训练”分区的预测正确率,两个模型都很高;对于“2_ 测试”分区的预测正确率,Class-rbf 的结果稍高。总体而言,两个模型差不多,Class-rbf 的预测能力稍好。
通过比较,找到最合适核函数创建模型,将创建的模型用于信用评估。
利用模型评估客户信用
确定最合适核函数,创建相应模型,应用此模型评估客户信用。为了评估客户信用,首先添加一个 “可变文件”节点,编辑该节点,打开需要评估的客户信息数据集 ( 该数据集的 class 字段为空 )。添加“表”节点连接到该数据集,运行“表”节点,预览待评估的数据集。从 modeler 界面右上角的“模型”选项板中拖入选定的模型块到流, 将该“可变文件”节点连接至该模型块之后,在模型块之后添加“表”节点,运行该“表”节点,获得评估结果。
图 14. 应用模型评估客户信用图
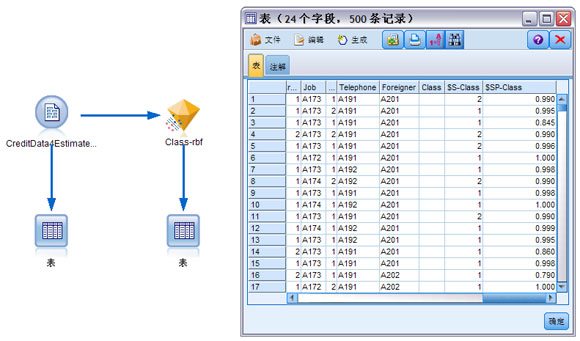
如图 14 中,左侧是用于评估的流,可见,用于评估的数据集连接到选定的模型 class-rbf。右侧是运行表节点的结果,因为这个数据集是用来评估的,class 字段是空,$S-class 字段是评估的结果,$P-class 是评估的可信程度。我们可以信任 $P-class 值是 0.95 及其以上的判断结果,对于小于 0.95 的值的判断结果,作为一定参考,再结合别的方法判断。
小结
本文通过一个实际的商业问题—银行评估客户,引入了 IBM SPSS Modeler 支持向量机(SVM)模型。首先给出了 SVM 的相关概念,接着带领读者一步步创建模型,分析模型,选择模型,应用模型来解决该实际问题。可以将本模型应用到其他的场景中,如基因分析、文本处理等领域,应用 SVM 可以取得理想的结果。
支持向量机比较容易理解,但是和函数的选择和参数的选择都还不是非常的清楚。