在旧版SPSS软件中如果要做典型相关分析,我们需要用简单的语法语句调取自带的宏程序,输出的结果以文本为主,没有成体系的表格,结果解读也相对繁琐。

相对较新的一些SPSS版本,已经基于Python内置了一个典型相关分析的菜单模块,你在安装SPSS软件时,一定要选择安装Python插件,否则也不会看到这个菜单。
市面上的多数SPSS图书要么没有讲解该方法,要么还是使用宏程序,为了让读者们实践起来方便一些,小兵这里用SPSS24.0来演示这个崭新的菜单过程,随后会录制视频更新到课程中去。
案例数据与方法介绍
为了研究兄长的头型和弟弟的头型间的关系,研究者随机抽查了25个家庭的两兄弟的头长和头宽数据,希望求得两组变量的典型相关系数。显然兄长的头型的long1和width1是第一组变量,弟弟头型的long2和width2为第二组变量。(引自张文彤图书)
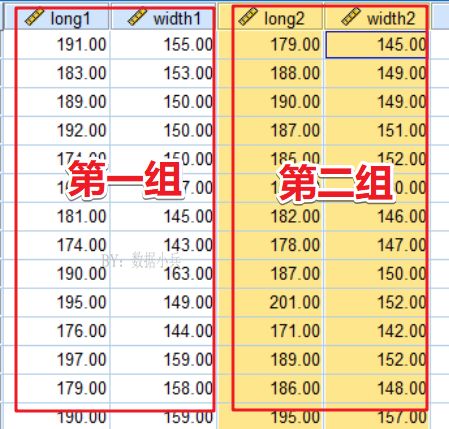
大家注意啊,我们是研究第一组变量(long1和width1)与第二组变量long2和width2,两组变量数据间的相关性,可不是以前说的两个变量间(比如身高和肺活量)的相关性。显然普通的两变量相关性分析根本解决不了这个问题。
能解决两组变量间相关性考察任务的统计方法,统计上叫做典型相关分析,英文名称为Canonical Correlation,由统计学家Hotelling在1936年提出。
SPSS典型相关分析菜单选项
菜单【分析】→【典型相关性】,这是基于Python插件做的菜单模块,安装时一定要全安装上。
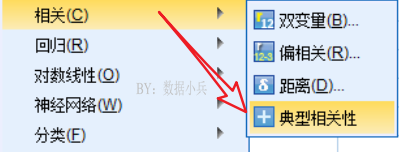
然后打开下方主对话框,逻辑上很清晰,我们要告诉软件第一组变量是long1和width1,第二组变量是long2和width2,就这么简单。
接下来,点开【选项】对话框,
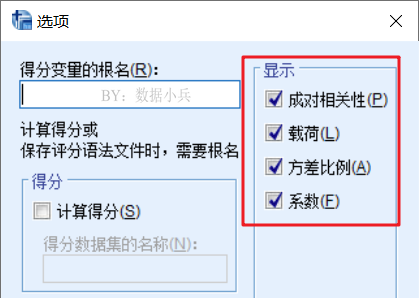
在软件默认勾选的载荷、方差比例、系数外,再勾选成对相关性。
好了,返回主对话框,点【确定】要求软件执行分析。
基本条件判断
典型相关分析有一个最基本的条件,我们要从第一组变量中抽取一(一个或两个)个虚拟的【典型变量】,就像主成分分析一样,假设提取一个叫做u1。同理我们从第二组变量中抽取出一个虚拟的【典型变量】,假设也是一个叫做v1。
u1是long1和width1的线性组合,v1是long2和width2的线性组合。凭什么能提取出这样的潜在变量呢,那它的基础条件就是每组变量内各变量存在一定程度的相关性,否则无法提取出来。
典型相关分析就是做这件事的,它要提取u1与v1,甚至是u2与v2。u1与v1叫做第一对典型变量,代表性最强,u2与v2叫做第二对典型变量,代表性次之。一般认为,只需要提取1~2对典型变量出来就可以充分概括两组变量的信息。
所以,首先我们要判断案例数据是不是组内变量具备一定相关性。
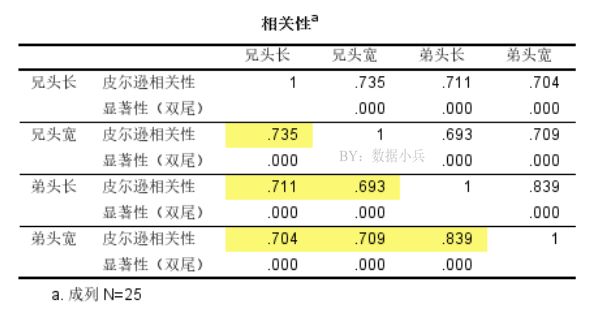
long1和width1相关系数0.735,,long2和width2相关系数0.839,组内的相关系数均在0.7以上,算是高度相关了。稳妥了,有了这个基础就能保证抽取出u和v。
然后我们也发现兄和弟之间的相关性也较高,最低0.693。可见我们狭义判断一下也会觉得兄和弟之间头型的数据有相关,这也让研究能继续下去。
相关系数
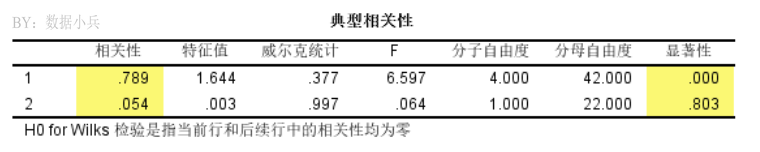
本例每组变量只有两个变量,所以最多每组提取2个【典型变量】。
最终呢SPSS帮我们抽提了2对【典型变量】。第一对【典型变量】u1和v1间的相关系数为0.789,经统计检验,有统计学意义(P<0.01),第二对【典型变量】的相关系数为0.054,无统计学意义(P>0.05)。
这是非常重要的结果,也是最终结果了。两队典型变量的相关性,我们只保留有统计学意义的。因此弟弟头型数据与兄长头型数据间的相关系数为0.789,高度相关。
这是基本结论。
典型变量
那么我现在想明确的知道这一对典型变量u1和v1到底长什么样子,它不是代表性最强吗?有多强?
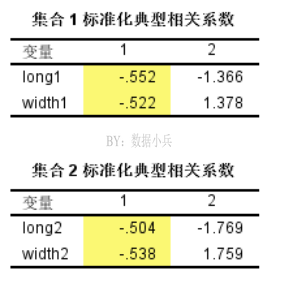
看这两个表格,编号1的列指的就是第一对典型变量,同理编号2的列指的是第二对典型变量。据此可写出u1和v1的表达式(系数统一取绝对值)。
u1=0.522*long1+0.522*width1
v1=0.504*long2+0.538*width2
就长这样了。
那它们各自代表第一组变量和第二组变量的信息程度有多大呢?看下表。

如上。第一对典型变量中的u1可解释第一组变量总变异的86.7%,很高吧。而v1能解释第二组变量总变异的92%。
而第二对典型变量分别解释的能力是13.3%和8%,很显然是非常低的比例,所以抛弃它不要了。
到此时,我们已经明确地得到:
1、兄长组提取出u1,弟弟组提取出v1,组成最强典型变量对(u1+v1);
2、u1和v1的代表性足够强,各自的解释能力在80%以上;
所以我们用u1和v1分别代表第一组变量数据,和第二组变量数据,其相关系数为0.789,弟弟头型数据与兄长头型数据高度相关,有统计学意义。
数据来源及参考资料:
张文彤《SPSS统计分析高级教程》
全文完
图/文=数据小兵