牛客网SQL练习总结
学习SQL之前请先安装好数据库和客户端(Navicat 或者 DBeaver):
SQL交流群:
前言
最近在学着做项目,代码敲少了怕手会生疏,所以每天增加点SQL的练习。之前做的SQLZOO练习题是专题式的,适合刚学习完理论知识后按专题吃透一个个知识点,而牛客网的练习题是综合式,更能锻炼逻辑思维,希望后期能锻炼到拿到一个需求就能“条件反射”的状态。
练习题
1.查找最晚入职员工的所有信息
方法一:
select * from employees
where hire_date in (select max(hire_date)
from employees);方法二:
select * from employees
order by hire_date desc
limit 0,1;【笔记】limit 0,1, 从你的表中的第0个数据开始,只读取一个,故表示第一个数,那么limit 1,1表示第二个数。
2.查找入职员工时间排名倒数第三的员工所有信息
select * from employees
order by hire_date desc
limit 2,1;3.查找各个部门当前(to_date='9999-01-01')领导当前薪水详情以及其对应部门编号dept_no
select s.*, dept_no
from salaries s inner join dept_manager m on s.emp_no=m.emp_no
where m.to_date='9999-01-01'
and s.to_date='9999-01-01';【笔记】假如两个表联结了之后,需要限定条件的字段在两个表里都有,那么对两个表中的该字段都要做限制。
4.查找所有已经分配部门的员工的last_name和first_name
select last_name, first_name, dept_no
from employees e left join dept_emp d on e.emp_no=d.emp_no
where dept_no is not null;5.查找所有员工的last_name和first_name以及对应部门编号dept_no,也包括展示没有分配具体部门的员工
select last_name, first_name, dept_no
from employees e left join dept_emp d on e.emp_no=d.emp_no;6.查找所有员工入职时候的薪水情况,给出emp_no以及salary, 并按照emp_no进行逆序
select e.emp_no, salary
from employees e left join salaries s on e.emp_no=s.emp_no
where hire_date = from_date
order by e.emp_no desc;7.查找薪水涨幅超过15次的员工号emp_no以及其对应的涨幅次数t
select emp_no, count(*) as t
from salaries
group by emp_no
having count(*) >= 15;8.找出所有员工当前(to_date='9999-01-01')具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示
select distinct salary
from salaries
where to_date='9999-01-01'
order by salary desc;9.获取所有部门当前manager的当前薪水情况,给出dept_no, emp_no以及salary,当前表示to_date='9999-01-01'
select dept_no, m.emp_no, salary
from dept_manager m left join salaries s on m.emp_no=s.emp_no
where m.to_date='9999-01-01'
and s.to_date='9999-01-01';10.获取所有非manager的员工emp_no
select e.emp_no
from employees e left join dept_manager m on e.emp_no=m.emp_no
where dept_no is null;11.获取所有员工当前的manager,如果当前的manager是自己的话结果不显示,当前表示to_date='9999-01-01'。
结果第一列给出当前员工的emp_no,第二列给出其manager对应的manager_no。
select e.emp_no, m.emp_no
from dept_emp e inner join dept_manager m on e.dept_no=m.dept_no
where e.to_date='9999-01-01'
and m.to_date='9999-01-01'
and e.emp_no != m.emp_no;12.获取所有部门中当前员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary
select dept_no, e.emp_no, max(salary)
from dept_emp e inner join salaries s on e.emp_no=s.emp_no
where e.to_date='9999-01-01'
and s.to_date='9999-01-01'
group by dept_no;【使用group by笔记】:
①group by一般和聚合函数(count sum avg max min)一起使用才有意义;
②假如用到group by,那么出现在select后面的字段,要么是聚合函数count sum avg max中的,要么就是group by中的字段;(经验:group by班级名字,select班级名字,班级代码,就算知道班级名字和班级代码是一一对应关系,还是会报错,要改成“group by 班级名字,班级代码”);
③筛选结果:可以先使用where 再用group by 或者先用group by 再用having;
④group by 两个字段:将两个字段看为一个整体,只有两个字段均相同才会分为一组。
13.从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t
select title, count(*) as t
from titles
group by title
having count(*)>=2;14.从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
注意对于重复的emp_no进行忽略
select title, count(distinct emp_no) as t
from titles
group by title
having count(distinct emp_no)>=2;15.查找employees表所有emp_no为奇数,且last_name不为Mary的员工信息,并按照hire_date逆序排列
select *
from employees
where emp_no %2 =1
and last_name != 'Mary'
order by hire_date desc;16.统计出当前各个title类型对应的员工当前薪水对应的平均工资。
结果给出title以及平均工资avg
select title, avg(salary)
from salaries s inner join titles t on s.emp_no=t.emp_no
where s.to_date='9999-01-01'
and t.to_date='9999-01-01'
group by title;17.获取当前(to_date='9999-01-01')薪水第二多的员工的emp_no以及其对应的薪水salary
select emp_no, salary
from salaries
where to_date='9999-01-01'
order by salary desc
limit 1,1;18.查找当前薪水(to_date='9999-01-01')排名第二多的员工编号emp_no、薪水salary、last_name以及first_name,不准使用order by
select e.emp_no, max(salary), last_name, first_name
from employees e inner join salaries s on e.emp_no=s.emp_no
where salary not in (select max(salary)
from salaries)
and s.to_Date='9999-01-01';【笔记】假如是select某限制条件对应的全部信息,该限制信息要写在where语句里,但假如是select最大值/最小值/平均值对应的信息,直接全部写在select里就行(例如:select name, max(salary), age)。
19.查找所有员工的last_name和first_name以及对应的dept_name,也包括暂时没有分配部门的员工
select last_name, first_name, dept_name
from (employees e left join dept_emp de on e.emp_no=de.emp_no)
left join departments d on de.dept_no=d.dept_no;20.查找员工编号emp_no为10001其自入职以来的薪水salary涨幅值growth
select (max(salary)-min(salary)) as growth
from salaries
where emp_no=10001;21.查找所有员工自入职以来的薪水涨幅情况,给出员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序
select a.emp_no, (a.salary-b.salary) as growth
from (select e.emp_no, salary
from employees e left join salaries s on e.emp_no=s.emp_no
where to_date='9999-01-01') as a
inner join (select e.emp_no, salary
from employees e left join salaries s on e.emp_no=s.emp_no
where from_date = hire_date) as b
on a.emp_no=b.emp_no
order by growth;【思路】想象先建立两张表,分别存放员工当前工资(sCurrent)与员工入职时的工资(sStart),再用INNER JOIN连接sCurrent与sStart,最后限定在同一员工下用当前工资减去入职工资。
22.统计各个部门对应员工涨幅的次数总和,给出部门编码dept_no、部门名称dept_name以及次数sum
select de.dept_no, dept_name, count(salary) as sum
from dept_emp de inner join departments d on de.dept_no = d.dept_no
inner join salaries s on de.emp_no = s.emp_no
group by de.dept_no;23.对所有员工的当前(to_date='9999-01-01')薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列
select s2.emp_no, s2.salary, count(distinct s1.salary) as rank
from salaries s1, salaries s2
where s1.to_date='9999-01-01'
and s2.to_date='9999-01-01'
and s1.salary>=s2.salary
group by s2.emp_no
order by rank, s2.emp_no;【笔记】复用salaries表进行排名的比较,某数据排名第三的意思是:在去重之后,该字段有三个数据是大于等于该数。
①将s2设为主表,s1设为对比表,计算s1表大于等于s2表某数据的个数即s2该数据的排名;
②注意表s2要使用group by分组,才能使得表s2每个人的工资都与对比表s1进行比较,否则查询结果只有一条数据;
③注意SQLite不支持ROW_NUMBER。假如使用ROW_NUMBER语句:
select emp_no, salary, row_number() over(order by salary desc) as rank
from salaries
where to_date='9999-01-01'
order by salary desc, emp_no;【笔记】:ROW_NUMBER
①假如是需要直接输出排序,例子如上;
②假如是需要排序后,查询某个排名的信息,则要用两个select。
场景:一个客户打电话来投诉,客服记录了她投诉的类别,但是可能第一次判断的分类不准确,所以数据库里面一条投诉会有很多记录。比如说:
11月2号 8点 分类为1
11月3号 9点 分类为3
11月4号 10点 分类为5
那么我们要查看投诉情况的话,直接取最新的记录就好了,其他记录就不用再拉出来。
select id
from (select row_number() over(partition by ticket order by time desc) rank
from customer)
where rank=1;24.获取所有非manager员工当前的薪水情况,给出dept_no、emp_no以及salary ,当前表示to_date='9999-01-01'
select de.dept_no, de.emp_no, salary
from dept_emp de left join salaries s on de.emp_no=s.emp_no
where de.to_date='9999-01-01'
and s.to_date='9999-01-01'
and de.emp_no not in (select emp_no
from dept_manager);【笔记】没办法做三表联结然后根据某个字段是null来筛选(对比第10题),因为表dept_manager的字段和表dept_emp的相同。
25.获取员工其当前的薪水比其manager当前薪水还高的相关信息,当前表示to_date='9999-01-01',
结果第一列给出员工的emp_no,
第二列给出其manager的manager_no,
第三列给出该员工当前的薪水emp_salary,
第四列给该员工对应的manager当前的薪水manager_salary
select
e.emp_no,
m.emp_no as manager_no,
e.salary as emp_salary,
m.salary as manager_salary
from (select de.emp_no, dept_no, salary
from dept_emp de inner join salaries s on de.emp_no = s.emp_no
where de.to_date='9999-01-01'
and s.to_date='9999-01-01') e
inner join(select dm.emp_no, dept_no, salary
from dept_manager dm inner join salaries s on dm.emp_no = s.emp_no
where dm.to_date='9999-01-01'
and s.to_date='9999-01-01') m
on e.dept_no = m.dept_no
where e.salary > m.salary;【思路】同第21题。
26.汇总各个部门当前员工的title类型的分配数目,结果给出部门编号dept_no、dept_name、其当前员工所有的title以及该类型title对应的数目count
select d.dept_no, dept_name, title, count(*)
from dept_emp de left join titles t on de.emp_no = t.emp_no
left join departments d on de.dept_no = d.dept_no
where de.to_date='9999-01-01'
and t.to_date='9999-01-01'
group by de.dept_no, title;27.给出每个员工每年薪水涨幅超过5000的员工编号emp_no、薪水变更开始日期from_date以及薪水涨幅值salary_growth,并按照salary_growth逆序排列。
提示:在sqlite中获取datetime时间对应的年份函数为strftime('%Y', to_date)
select s2.emp_no, s2.from_date, (s2.salary - s1.salary) as salary_growth
from salaries s1 inner join salaries s2 on s1.emp_no = s2.emp_no
where s2.salary - s1.salary > 5000
and strftime('%Y',s2.to_date) - strftime('%Y',s1.to_date) = 1
order by salary_growth desc;【笔记】复用salaries表计算每年薪水涨幅,思路同23题。
28.查找描述信息中包括robot的电影对应的分类名称以及电影数目,而且还需要该分类对应电影数量>=2部
select c.name, count(fc.film_id)
from film_category fc inner join category c on fc.category_id = c.category_id
inner join film f on fc.film_id = f.film_id
where f.description like '%robot%'
group by c.name
having count(fc.film_id) >= 2;29.使用join查询方式找出没有分类的电影id以及名称
select f.film_id, f.title
from film f left join film_category fc on f.film_id = fc.film_id
where fc.category_id is null;30.使用子查询的方式找出属于Action分类的所有电影对应的title,description
select title, description
from film
where film_id in (select film_id
from film_category
where category_id in (select category_id
from category
where name = 'Action'));31.获取select * from employees对应的执行计划
explain select * from employees;【笔记】在 SQLite 语句之前,可以使用 "EXPLAIN" 关键字或 "EXPLAIN QUERY PLAN" 短语,用于描述表的细节。如果省略了 EXPLAIN 关键字或短语,任何的修改都会引起 SQLite 语句的查询行为,并返回有关 SQLite 语句如何操作的信息。
32.将employees表的所有员工的last_name和first_name拼接起来作为Name,中间以一个空格区分
select last_name||" "||first_name as name
from employees;【笔记】不同数据库连接字符串的方法不完全相同,MySQL、SQL Server、Oracle等数据库支持CONCAT方法,而本题所用的SQLite数据库只支持用连接符号"||"来连接字符串。
33.创建一个actor表,包含如下列信息:

create table actor
(
actor_id smallint(5) not null primary key,
first_name varchar(45) not null,
last_name varchar(45) not null,
last_update timestamp not null default(datetime('now','localtime'))
);【笔记】获取系统默认时间是datetime('now','localtime')
34.对于表actor批量插入如下数据:

insert into actor
values (1,'PENELOPE','GUINESS','2006-02-15 12:34:33'),(2,'NICK','WAHLBERG','2006-02-15 12:34:33');35.对于表actor批量插入如下数据,如果数据已经存在,请忽略,不使用replace操作

insert or ignore into actor
values(3,'ED','CHASE','2006-02-15 12:34:33');36.对于如下表actor,其对应的数据为:
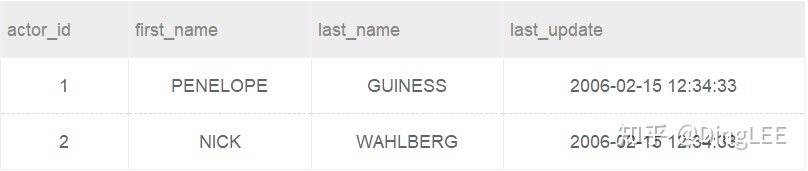
创建一个actor_name表,将actor表中的所有first_name以及last_name导入改表。 actor_name表结构如下:
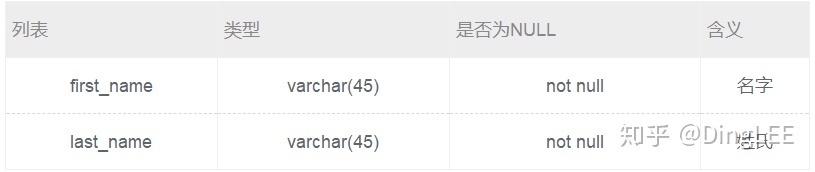
create table actor_name
(
first_name varchar(45) not null,
last_name varchar(45) not null
);
insert into actor_name select first_name, last_name from actor;37.针对如下表actor结构创建索引:对first_name创建唯一索引uniq_idx_firstname,对last_name创建普通索引idx_lastname
create unique index uniq_idx_firstname on actor(first_name);
create index idx_lastname on actor(last_name);【笔记】索引就像书的目录, 通过书的目录就准确的定位到了书籍具体的内容。索引的建立对于SQL的高效运行是很重要的,索引可以大大提高SQL的检索速度。实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
38.针对actor表创建视图actor_name_view,只包含first_name以及last_name两列,并对这两列重新命名,first_name为first_name_v,last_name修改为last_name_v
create view actor_name_view(first_name_v, last_name_v) as
select first_name, last_name
from actor;【笔记】视图是虚拟的表,与包含数据的表不一样,视图只包含使用时动态检索数据的查询。
39.针对salaries表emp_no字段创建索引idx_emp_no,查询emp_no为10005, 使用强制索引
select *
from salaries
indexed by idx_emp_no
where emp_no=10005;【笔记】SQLite中,使用 INDEXED BY 语句进行强制索引查询;MySQL中,使用 FORCE INDEX 语句进行强制索引查询。
40.现在在last_update后面新增加一列名字为create_date, 类型为datetime, NOT NULL,默认值为'0000 00:00:00'
alter table actor
add column create_date datetime not null default '0000-00-00 00:00:00';【笔记】ALTER TABLE ... ADD ...语句可以向已存在的表插入新字段。
41.构造一个触发器audit_log,在向employees_test表中插入一条数据的时候,触发插入相关的数据到audit中。
create trigger audit_log after insert on employees_test
begin
insert into audit values (new.id,new.name);
end;【笔记】触发器
① 创建触发器使用语句:CREATE TRIGGER trigname;
② 指定触发器触发的事件在执行某操作之前还是之后,使用语句:BEFORE/AFTER [INSERT/UPDATE/ADD] ON tablename
③ 触发器触发的事件写在BEGIN和END之间
④可以使用 NEW与OLD 关键字访问触发后或触发前的employees_test表单记录
42.删除emp_no重复的记录,只保留最小的id对应的记录
delete from titles_test
where id not in(select min(id)
from titles_test
group by emp_no);43.将所有to_date为9999-01-01的全部更新为NULL,且 from_date更新为2001-01-01
update titles_test
set to_date=null, from_date='2001-01-01'
where to_date='9999-01-01';【笔记】注意alter和update的区别,要增加字段、改表名用alter,改变表中的数据用update、replace。
44.将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005,其他数据保持不变,使用replace实现
①全字段更新替换
replace into titles_test values('5', '10005', 'Senior Engineer', '1986-06-26', '9999-01-01');②运用REPLACE(X,Y,Z)函数。其中X是要处理的字符串,Y是X中将要被替换的字符串,Z是用来替换Y的字符串,最终返回替换后的字符串
update titles_test set emp_no=replace(emp_no,10001,10005)
where id=5;【笔记】假如不是题目要求用replace,可以用update来实现:
update titles_test set emp_no=10005 where id=5;45.将titles_test表名修改为titles_2017
alter table titles_test rename to titles_2017;46.如何获取emp_v和employees有相同的数据?
select *
from employees
where emp_no>10005;47.将所有获取奖金的员工当前的薪水增加10%
update salaries set salary = salary*1.1
where emp_no in (select emp_no
from emp_bonus);48.将employees表中的所有员工的last_name和first_name通过(')连接起来
select last_name|| "'" ||first_name
from employees;49.查找字符串'10,A,B' 中逗号','出现的次数cnt
select length('10,A,B')-length(replace('10,A,B',",","")) as cnt;50.获取Employees中的first_name,查询按照first_name最后两个字母,按照升序进行排列
select first_name
from employees
order by substr(first_name,length(first_name)-1,2);【笔记】本题考查 substr(X,Y)或substr(X,Y,Z) ,其中X是要截取的字符串,Y是字符串的起始位置,Z是要截取字符串的长度。
51.按照dept_no进行汇总,属于同一个部门的emp_no按照逗号进行连接,结果给出dept_no以及连接出的结果employees
select dept_no,group_concat(emp_no) as employees
from dept_emp
group by dept_no;【笔记】SQLite的聚合函数group_concat(X,Y),其中X是要连接的字段,Y是连接时用的符号,可省略,默认为逗号。此函数必须与 GROUP BY 配合使用。
52.查找排除当前最大、最小salary之后的员工的平均工资avg_salary
select avg(salary) as avg_salary
from salaries
where to_date='9999-01-01'
and salary not in (select max(salary)
from salaries)
and salary not in (select min(salary)
from salaries);53.分页查询employees表,每5行一页,返回第2页的数据
select *
from employees
limit 5,5;54.使用含有关键字exists查找未分配具体部门的员工的所有信息
select *
from employees
where not exists (select emp_no
from dept_emp
where emp_no=employees.emp_no);【笔记】可以用in来替代exists:
select *
from employees
where emp_no not in (select emp_no
from dept_emp
where emp_no=employees.emp_no);55.获取有奖金的员工相关信息
select e.emp_no, e.first_name, e.last_name, btype, salary,
(case btype
when 1 then salary*0.1
when 2 then salary*0.2
else salary*0.3
end) as bonus
from (employees e inner join emp_bonus b on e.emp_no=b.emp_no)
inner join salaries s on e.emp_no=s.emp_no
where s.to_date='9999-01-01';56.按照salary的累计和running_total,其中running_total为前两个员工的salary累计和,其他以此类推
select s1.emp_no, s1.salary,
(select sum(s2.salary)
from salaries s2
where s2.to_date='9999-01-01'
and s1.emp_no>=s2.emp_no )as running_total
from salaries s1
where s1.to_date='9999-01-01';57.对于employees表中,给出奇数行的first_name
select e1.first_name
from employees e1
where (select count(*)
from employees e2
where e1.first_name>=e2.first_name)%2=1 ;
from 牛客网SQL练习总结 - 知乎 (zhihu.com)