来自 http://blog.163.com/shen_960124/blog/static/6073098420136161844551/
对比正常情况下的顺序访问,索引可以为以下操作提供观测的直接访问:
访问较少于总体的子集(WHERE)
返回已排序的观测(BY)
进行表查询操作(使用KEY=的SET语句)
连接观测(PROC SQL)
修改观测(使用KEY=的MODIFY语句)
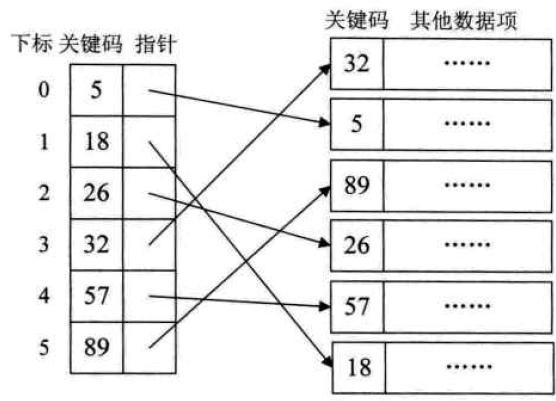
索引是一种辅助的数据结构,基于一个或则多个关键变量来指明观测的位置。
SAS数据集索引的结构如上图,它保存着已排序的关键值(Key Value),和关键值出现的位置(Location)。其中页(page)是可以在一次I/O请求中完成传输的数据集合(一组观测)。每个数据文件都有预先指定的页大小,配置适当的页大小可以大大优化访问速度。
在没有使用索引时,任何的查询都要遍历所有的纪录。使用索引后,SAS只读出满足查询条件的页。如果满足查询条件的页大大小于整个数据集,查询速度当然得到极大的提高。如果这些页接近整个数据集,由于使用索引还要增加读取索引文件的开销,查询数据反而会降低。SAS中的语言优化器会自动判断是否需要使用索引。
SAS索引有两大类:
简单索引,只基于一个变量的值,索引名自动等于其关键变量名。
复合索引,基于多于一个变量组合成的值,必须有一个表级的唯一名。
索引常用的选项有: UNIQUE:关键变量的取值必须为一。该选项防止对于关键变量冗余的记录加入到数据集中。
建立索引:
可以在建立数据集同时建立索引。在数据步中,输出数据集选项使用INDEX=选项。
可以使用SQL过程,或者DATASETS过程,在现存的数据集上建立索引。
一般而言,建立索引有三步
1. 标出关键变量
2. 如果是复合索引,选择有效的SAS名称作为索引名
3. 确定索引选项
一个数据集可以拥有:
多个简单和复合索引
字符型和数字型的关键变量
在实际使用中,出于效率考虑,我们只会为经常在WHERE条件中使用的变量,和用来合并SAS数据集的变量建立索引。
在数据步中建立索引
语法:
DATA SAS-data-file-name(INDEX =
(index-specification-1
…>));
例如:
/* 建立简单索引 */
DATA class(INDEX=(age));
SET sashelp.class;
RUN;
/* 建立一个简单索引和一个复合索引i_ah */
DATA class(INDEX=(age i_ah=(age height)));
SET sashelp.class;
RUN;
使用全局选项 MSGLEVEL=,你可以在日志中看到索引的建立,使用情况。
语法:
OPTIONS MSGLEVEL = N | I
N:仅打印notes, warnings,和error 信息。系统的默认选项。
I:打印N选项的信息,同时打印附属信息,包括索引使用,合并处理,排序等附加信息。
使用DATASETS过程管理索引
语法:
PROC DATASETS LIBRARY = libref ;
MODIFY SAS-data-set-name;
INDEX DELETE index-name;
INDEX CREATE index-specification
;
QUIT;
如果同名索引已经存在,INDEX CREATE语句将不能建立新的索引。
如果INDEX DELETE和INDEX CREATE在同一个过程步出现,INDEX DELETE会先执行,以便为建立新索引留下可用空间。
例如:
options msglevel = i;
proc datasets library = ia nolist;
modify sale2000;
index delete Origin;
index delete FlightDate;
index create Origin;
index create FlightDate =
(FlightID Date) / unique;
quit;
使用SQL过程管理索引
语法:
PROC SQL;
CREATE INDEX index-name
ON table-name(column-name-1,…
column-name-n);
DROP INDEX index-name
FROM table-name;
QUIT;
同样,如果同名索引已经存在,必须删除才能使用语句重新建立。
例如:
options msglevel = i;
proc sql;
drop index Origin
from ia.Sale2000;
drop index FlightDate
from ia.Sale2000;
create index Origin
on ia.Sale2000(Origin);
create unique index FlightDate
on ia.Sale2000(FlightID,Date);
quit;
索引的存储
索引与被索引的数据集存放在同一个SAS逻辑库中。同时,索引是一个与数据集分离的SAS文件。一个索引文件可能包含单一数据集的多个索引。在z/OS操作系统文件列表上,索引文件不会像其他单独文件一样显示出来。
索引文件的命名:与被索引的数据集文件同名,后缀名为sas7bndx(SAS8以上)。例如:对于数据集sale2000,其数据文件名为sale2000.sas7bdat,索引文件名为sale2000.sas7bndx。
索引的内容可以通过以下方法查询:
PROC CONTENTS
PROC DATASETS
SAS浏览器
维护索引
以下列出不同数据管理任务对索引的影响
数据任务 -> 索引操作
使用COPY过程/DATASETS过程/SAS浏览器拖放操作复制数据 -> 为新数据文件建立索引文件
使用PROC COPY的MOVE选项移动数据 -> IN=逻辑库中的索引被删除,OUT=逻辑库中的索引被重建。
数据集重命名 -> 索引文件重命名
关键变量重命名 -> 索引文件中的相应变量也重命名
增加/删除/更新观测 -> 添加/删除/更新索引中的值/数据位置记录。
删除数据集/使用数据步重建数据集/使用FORCE选项对数据集自身排序 -> 删除索引文件。
另外,某些过程用选项控制是否复制索引。如UPLOAD和DOWNLOAD过程,默认为复制索引,通过INDEX=NO选项来禁止复制索引。
当以下情况满足时,SAS不会使用索引:
在数据步中使用IF语句取子集。
WHERE表达式只有部分包含关键变量。
SAS检测出顺序读取数据更有效率。
索引使用案例:(使用options msglevel = i;观察索引使用情况)
案例1:不使用索引。
options msglevel = i;
data rdu2000;
set ia.sale2000;
if Origin = ‘RDU’;
run;
案例2:不使用索引。
proc print data = ia.sale2000;
where Origin = ‘RDU’ or Date = ’01dec2000’d;
run;
案例3:不使用索引。
proc print data = ia.sale2000;
where Origin ne ‘RDU’;
run;
案例4:使用索引。
proc print data = ia.sale2000;
where Origin = ‘ATH’;
run;
案例5:使用索引。
proc print data = ia.sale2000;
where FlightID = ‘IA07400’;
run;
对于玩数据库的人来说,这些都是常识了吧。