前言
对于最终客户来说,自动化的机器学习工具(AUTO ML)无疑是很有吸引力的。就像iPhone一样,很多app无需设置参数,都是傻瓜式的操作。虽然有一些制约,但是多数情况下这样的用户体验却是很好。
今天我们推荐的pycaret 便是致力于自动化机器学习的python 库,它还无法面向最终用户,因为它没有GUI。但是低代码的优势,让它离这个目标很近,相信很多网页开发者可以很轻易地以pycaret为核心,开发出面向最终用户的机器学习平台。今年8月份,pycaret更新到2.0 版本,新增加了AUTO ML 应用,以及集成了ML FLOW来管理机器学习模型的“生产过程”。
极简产品体验
pycaret从安装到使用,让人察觉不出这是一款重量级的软件。
- 安装pycaret
pycaret安装很简单,使用pip即可。如果需要解释模型,需要安装SHAP。
pip install pycaret
pip install shap - 入门pycaret
使用pycaret,最好的环境是Jupyter,但是我习惯了pycharm,所以以下测试都是在pycharm中完成。
低代码意味着几乎是会用python就得到足够优秀的模型。以下不到十行代码就完成模型的完整部署,而且每个函数几乎都是只需一个位置参数。
- 读取数据–> pandas 读取即可
- 数据预处理–> setup 函数搞定
- 创建模型–>create_model 函数搞定
- 验证/预测模型–>predict_model 函数
- 查看结果–>plot_model
- 最终确认模型–>finalize_model 函数
- 解释模型–>interpret_model 函数
- 查看试验过程–>get_logs
from pycaret.classification import setup, get_logs,compare_models, create_model, predict_model, tune_model, finalize_model, plot_model, interpret_model
import pandas as pd
file = 'data/HR_Data_Predict Employee Turnover.csv'
raw_df = pd.read_csv(file)
expri_1 = setup(raw_df, target='left',log_experiment= True) # minimum parameters
lightgbm_model = create_model('lightgbm')
predict_model(lightgbm_model)
plot_model(lightgbm_model)
finalize_model(lightgbm_model)
interpret_model(lightgbm_model)
logs = get_logs(save=True)
print(logs)不得不说,虽然是开源,软件有着工业级别的成熟度。以上是员工离职率数据集的分析过程,所有的参数都是默认参数,只是采用lightgbm模型进行建模,没有使用额外的模型集成或者单个模型调优。
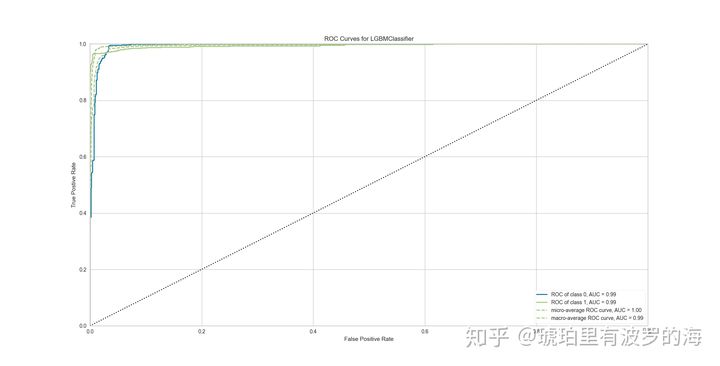
- plot_model(lightgbm_model),模型的AUC达到了0.99
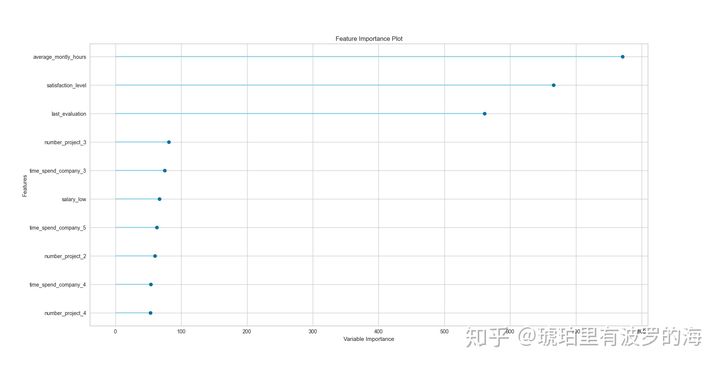
- plot_model(lightgbm_model,’feature’),可以查看模型的特征重要度。
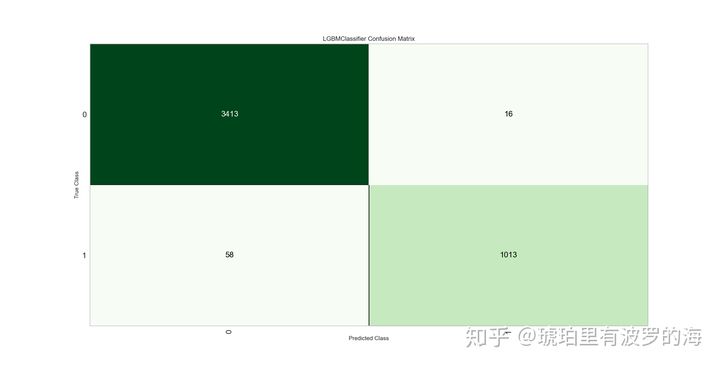
- plot_model(lightgbm_model,’confusion_matrix’),用于查看confusion_matrix。
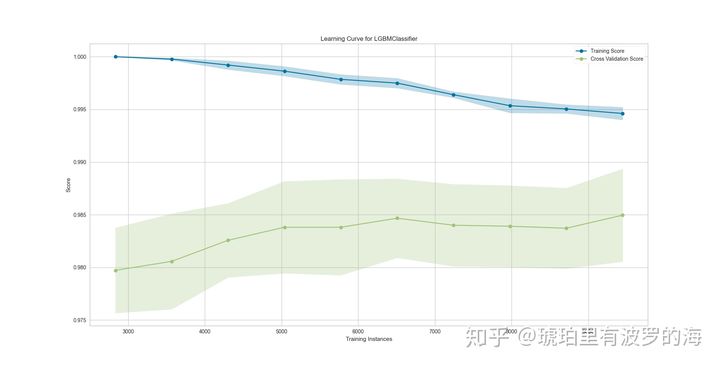
- plot_model(lightgbm_model,‘learning’),可以查看学习曲线。
- interpret_model(lightgbm_model),用于可视化解释模型。

绝佳的开源教程
很多人在学习建模时都想找优秀的教程(含代码)来参考,pycaret可以算是绝佳的开源教程。因为它包含了建模所有必须环节以及支持环节。通过学习和分析pycaret的处理流程,可以学习数据处理和建模的逻辑,因为pycaret已经总结出来很多优秀的”套路“。
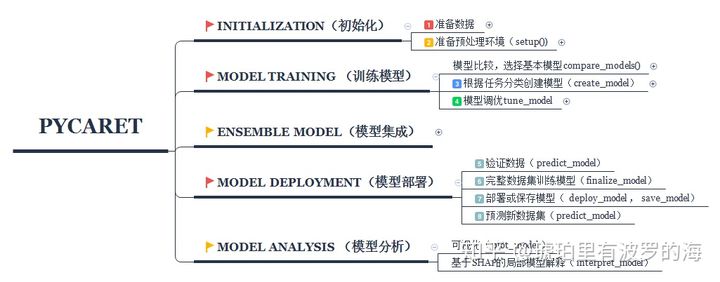
对于建模来说,很多情况我们会花大量的时间(大于50%的项目时间)来进行数据的清理,特征选择,特征工程的等预处理操作。pycaret仅仅用了一个setup函数便囊括了。在分析了源码的情况下,我发现pycaret的预处理套路真的“大而全”。
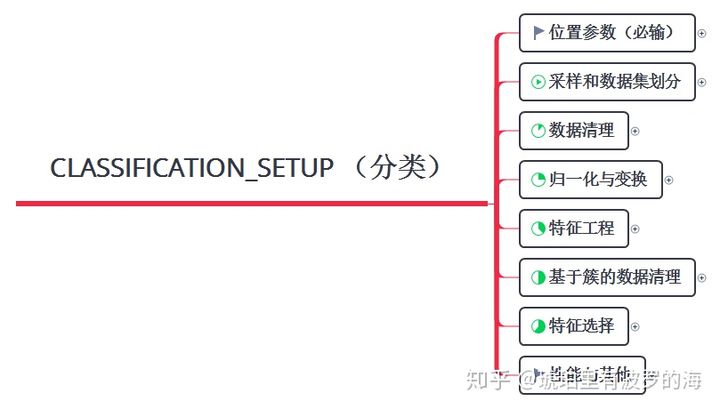
比如特征工程这个环节,特征交叉,多项式特征,基于统计的特征等方法都在其中。
特征选择也支持多种方法,比如基于特征重要性,基于主成分分析,基于低方差阈值等方法。点击大图可以查看所有预处理的流程,以及在setup中对应的参数,也就是该图是setup的cheat sheet。
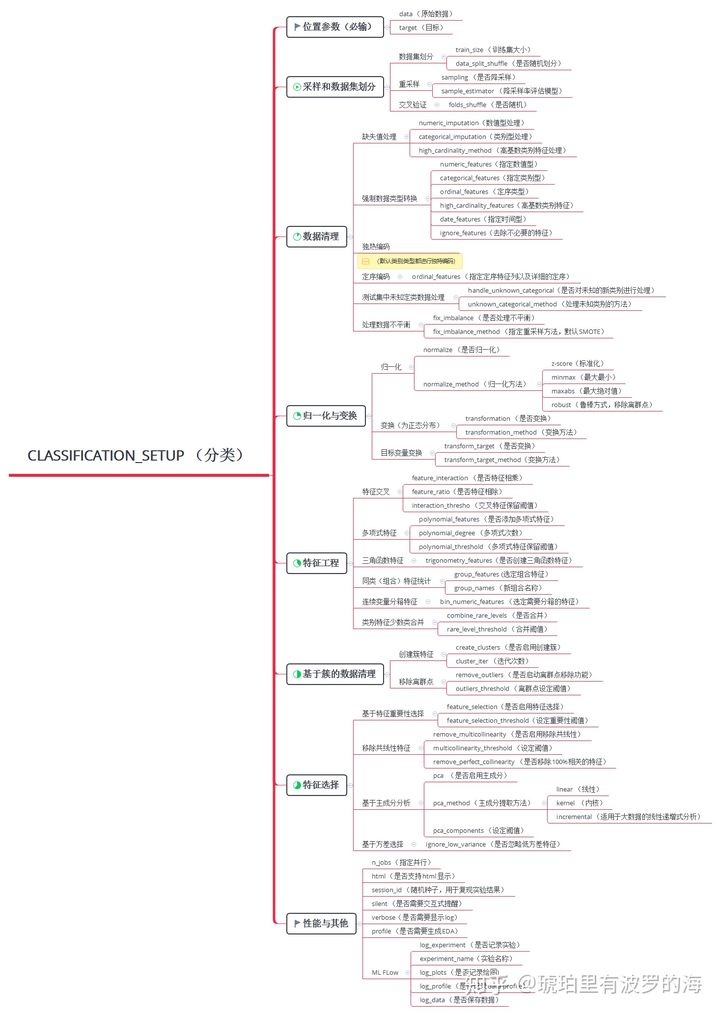
除了预处理方法(套路)“大而全”,代码的编写方法也值得学习。以下代码选自https://github.com/pycaret/pycaret/tree/master/pycaret。可以看到作者采用Pipeline来管理繁多的预处理流程,使得预处理流程一目了然,也方便后续扩展和维护。
pipe = Pipeline([
('dtypes',dtypes),
('imputer',imputer),
('new_levels1',new_levels1), # specifically used for ordinal, so that if a new level comes in a feature that was marked ordinal can be handled
('ordinal',ordinal),
('cardinality',cardinality),
('znz',znz),
('club_R_L',club_R_L),
('new_levels',new_levels),
('feature_time',feature_time),
('group',group),
('nonliner',nonliner),
('scaling',scaling),
('P_transform',P_transform),
('pt_target',pt_target),
('binn',binn),
('rem_outliers',rem_outliers),
('cluster_all',cluster_all),
('dummy',dummy),
('fix_perfect',fix_perfect),
('clean_names',clean_names),
('feature_select',feature_select),
('fix_multi',fix_multi),
('dfs',dfs),
('pca',pca)
])不仅是预处理环节,其他环节的处理方法都很齐全,比如,模型集成方式。这里我总结了代码中已经实现的集成方式,常见的bagging,boosting,blending,以及stacking都囊括其中。同样的,调用方式是极其简单。
bagged_dt = ensemble_model(dt, method = 'Bagging') # bagging
boosted_dt = ensemble_model(dt, method = 'Boosting', n_estimators = 100) #boost
blender_specific = blend_models(estimator_list = [dt,rf,adaboost], method = 'soft') #blending
stacker = stack_models(estimator_list = [ridge,lda,gbc], meta_model = xgboost) # stacking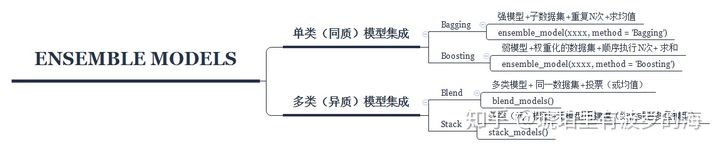
完整的模型生命周期管理
ML Flow 是用于管理机器学习模型生命周期的软件平台,它不仅仅支持python语言的模型管理,还支持其他多种语言的模型管理,比如R。这个软件平台包含多个核心模块,其中被调用最多的是ML flow tracking 模块。Pycaret 便集成了ML flow tracking 模块。
当在terminal中运行mlflow ui时,系统会出现模型管理的ML FlowGUI。这里会列出该experiment(实验)中每一次运行的参数,metrics,结果,以及最后的模型,当然,你可以选择保存每次实验中的绘图(plot)。
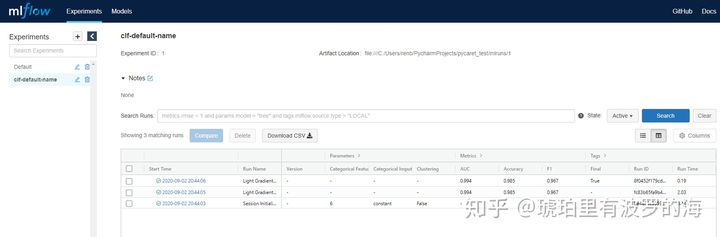
点击每个成功的运行,可以看到所有详细的参数。你也可以对比某些运行(runs)的参数以及结果。

总结
pycaret无论是从使用角度,设计角度,以及可扩展角度,在我看来都是很优秀的。本文仅仅是介绍了它的使用,以及通过源码和功能分析,简单发现它的部分优势。
后续我们会用pycaret去挑战一些更复杂的数据集来进一步验证它的效果,希望能不负所托。