(principal components analysis)
1.前期需要掌握的知识点及其相关课程:
⑴高等代数/线性代数:线性方程组、特征值和特征向量
⑵统计学:方差分析等
2.主成分分析思想:
主成分分析是利用降维的思想,在损失较少信息的前提下,用几个综合指标来代替之前多个指标的一种多元统计方法。我们把这些综合指标称为主成分,其中每一个主成分是原来变量的线性组合 ,并且各个主成分之间互不相关 。
3.主成分分析的几点要求
⑴每一个主成分都是原始变量的线性组合。
⑵主成分的数目要求远远小于原始变量的数目。
⑶主成分保留了原始变量绝大多数的信息。
⑷各个主成分之间互不相关。
4.选取主成分的几点选择方法
⑴累积贡献率达到85%。
⑵观察碎石图,当趋势变的平稳,则说明选取该主成分的数量比较合适。
⑶选取特征值大于1的主成分。
5.主成分的几个很重要的用途
⑴进行分类
我们可以通过主成分分析得到主成分得分,通过计算出总得分来进行分类,或者将前两个主成分得分放到四象限图中来进行分类。
⑵进行排名
通过主成分分析得到主成分得分,通过一定的手段计算出总得分来进行对样本的排名。
⑶ 主成分回归
由于在实际问题中,我们尽可能多的选取变量,这样会导致多重共线性问题的出现。主成分分析可以用少数几个综合变量来代替原始的变量,很有效的消除多重共线性。
实际例子(分类、排名)
在企业经济效益的评价中,设计的指标往往很多。为了可以简化系统结构,抓住经济效益评价的主要问题,我们用百元固定资产原值实现值、百元固定资产原值实现利税、百元资产实现利税、百元工业总产值实现利税、百元销售收入实现利税、每吨标准煤实现工业产值、每千瓦时电力实现工业产值、全员劳动生产率、百元流动资金实现产值,涉及到9项指标,28个样本数。
图1:相关矩阵
应该有这个意识,变量之间的存在着较强的相关性,主成分分析才会更加适用。而且如果原始大部分变量间的相关系数都小于0.3,运用主成分分析不会得到的很好的效果。经过图1,我们可以看到这9个变量之间的相关系数矩阵,我们发现变量间的相关性较强,适合运用主成分分析来进行后续的工作。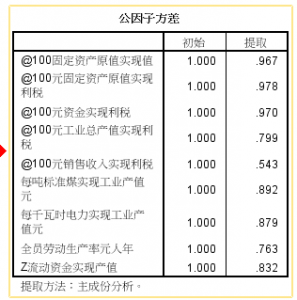
图2:信息提取率
上图是在主成分分析过程中从每一个变量中提取的信息。例如:百元固定资产原值实现值(96.7%)、百元固定资产原值实现利税(97.8%)、百元资产实现利税(97%)、百元工业总产值实现利税(79.9%)、百元销售收入实现利税(54.3%)、每吨标准煤实现工业产值(89.2%)、每千瓦时电力实现工业产值(87.9%)、全员劳动生产率(76.3%)、百元流动资金实现产值(83.2%)。
我们可以看到,除了百元销售收入实现利税(54.3%)信息损失的较多外,在其余变量提取的信息还是可以的。
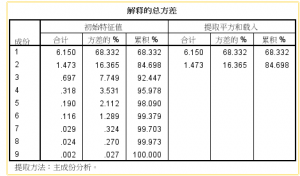
图3:方差贡献率
在提取主成分的时候,我们一般保留特征根大于1的主成分。在这个案例中,我们只保留前两个主成分,这样我们就可以在损失较少信息的前提下,用两个综合指标(主成分)来代替原始的9个变量,达到降维的效果。
(96.7%+97.8%+97%+79.9%+54.3%+89.2%+87.9%+76.3%+83.2%)/9=84.7%
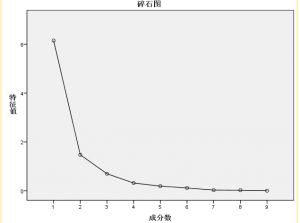
图4:碎石图
观察碎石图,我们发现第二个和第三个特征值的变化已经趋于平稳,则说明只提取两个或者三个主成分即可。
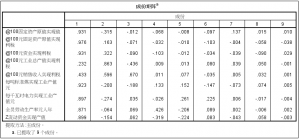
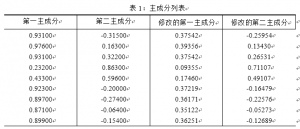
图5:载荷矩阵
虽然我们在选取主成分的时候,只需要选取前两个主成分即可,但是为了说明我们前面的主成分的性质,我们将这9个主成分全部列出。
在软件输出的结果中,我们得到的是因子载荷矩阵,而不是主成分的系数矩阵,因此我们要对因子载荷矩阵中的每一列除以对应的特征根的平方根 ,就可以得到主成分分析的系数。

我们利用以第一主成分为x轴,第二主成分为y轴,建立平面直角坐标系。并且用象限图来进行表示。
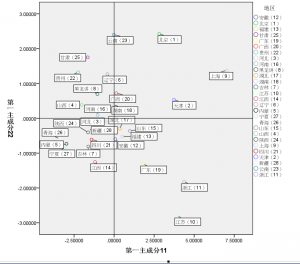
图6:四象限分布图
首先,分布在第一象限的是上海、北京、天津和广西四个省,这四个省的效益在全国属于比较好的(个人觉得不好,广西觉得不在这个范围里面)。第四象限的是湖北、山东、福建、安徽、广东、江苏、浙江7个省区,由于第四象限的主要特征第一主成分,第一主成分所占的信息较大,效益也不错。分布在第二三象限的为一类,效益不好。
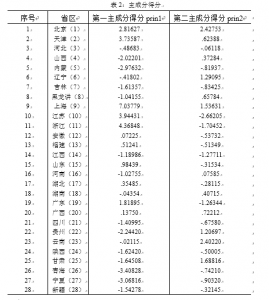
下面我们来计算总得分并且来对上面28个省区进行排名。

⑵由于第一主成分占用的信息量很大,因此我们可以第一主成分来进行排名,前提是第一主成分的系数必须全部为正数。
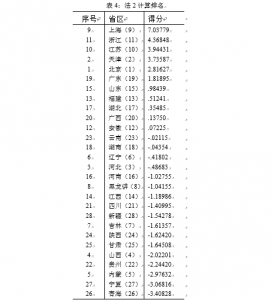
我们从上面的排名其实可可以进行聚类,以分数的形式呈现。
注:谢谢大家的聆听,欢迎提出宝贵意见,本人WeChat为sunzlxshine,可以多交流学习。