-

-
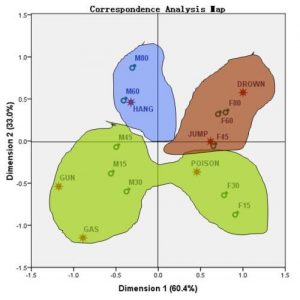
何为对应分析
定义:对应分析又称关联分析、R-Q型因子分析,主要是揭示变量样品之间的相互关系的多元统计方法
应用场景:主要用于市场细分、产品定位等方面研究
条件:变量是名义变量或定序变量,行变量的类别取值与列变量相互独立,行、列变量构成的交叉频数表中不能有0值或负数
优点: […]
-
SPSS因子分析操作步骤与结果分析
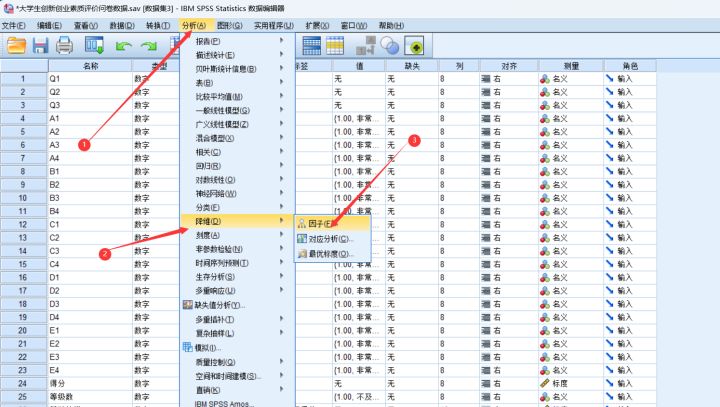
操作步骤
(1)分析——降维——因子(2)将量表题或者数据拖入变量匡中
(3)描述——勾选“初始解”——“KMO和巴特利特球形检验”KMO和巴特利特球形检验是因子分析的前提,只有KMO与巴特利特球形检验结果过了,才可以做因子分析。这里的KMO严格意义上来说只是能说明问卷或者所选数据适不适合做因子分析。但很多论文、硕士教育学中、大部分本科论文 […]
-
登上GitHub热榜的Python可视化工具:PyGWalker
 PygWalker是什么? PyGWalker(读作“Pig Walker”,谐音梗 ),全称为:Python Binding of Graphic Walker。 PyGWalker用于简化Jupyter Noteb […]
PygWalker是什么? PyGWalker(读作“Pig Walker”,谐音梗 ),全称为:Python Binding of Graphic Walker。 PyGWalker用于简化Jupyter Noteb […] -
简述:本文旨在带你快速开始使用Python进行uplift建模和因果推断,文章包括CausalML包安装方式和Python代码。英文原文来自https://github.com/uber/causalml,或可参考Causal ML。
Causal ML: 用于使用机器学习进行增益建模和因果推理的Python包
CausalML是一个Python包,它使用基于最近研究的机器学习算法提供了一套增益建模( […]
-
-
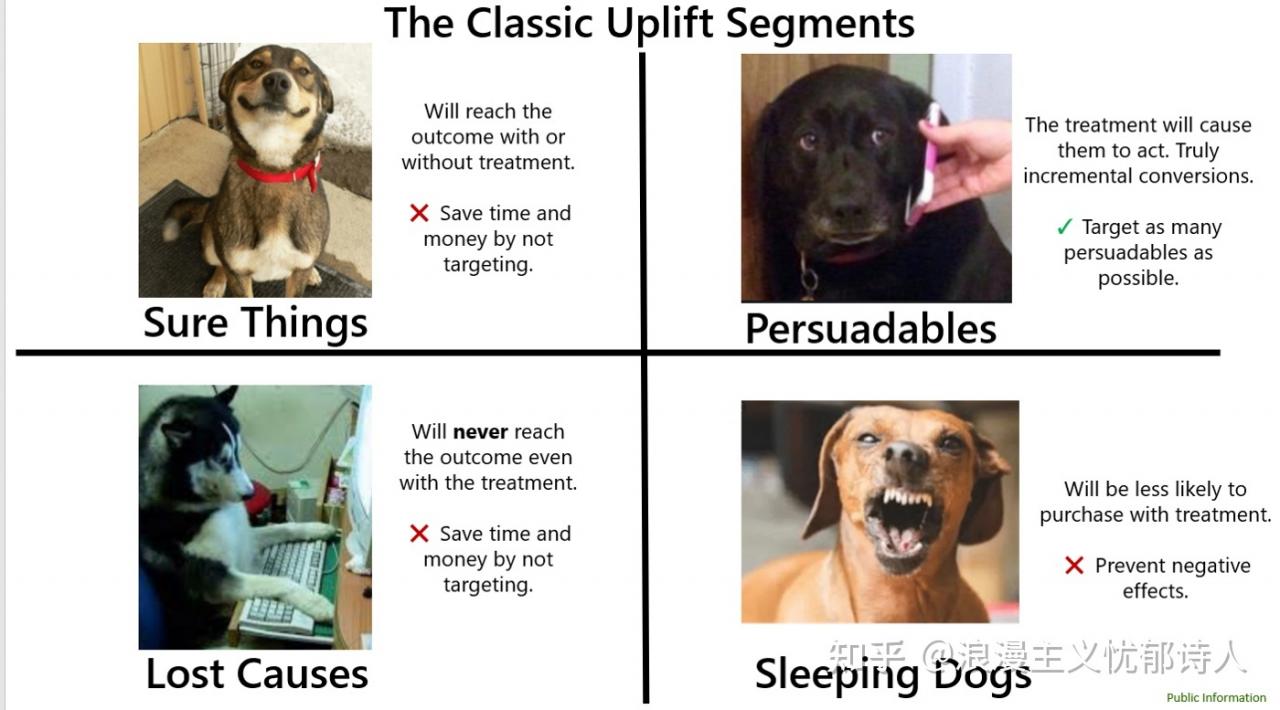
一句话总结Uplift Model:是使用用户分群的方法对用户进行精细化运营的一种手段
、什么是提升模型 – Uplift Model
传统的倾向性模型?propensity model 用来解决以下问题:客户将来有多大可能购买?
而更先进的提升模型 Uplift Model 则用来回答以下更重要的问题:
广告是否促使用户产生了消费意愿 […]
-
复杂的缺失值填补方法,会考虑到数据的整体情况,然后在对有缺失值的数据进行填充,本小节将会介绍3种复杂的缺失值填补方法。
数据准备## 输出高清图像
%config InlineBackend.figure_format = ‘retina’
%matplotlib inline
## 图像显示中文的问题
import matplotlib
matplotlib.rcP […]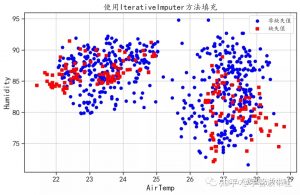
-
常见的数据框缺失数据插补有3种方式:
pandas 中简单粗暴的替换取值;
pandas 中的 fillna 函数;
sklearn 机器学习包中的 Imputer。经过一番对比之后,先上结论:pandas 的 fillna 函数功能最多,使用最灵活,所以可考虑用为 Python 数据插补工具的首选 […]

-
范叶亮 / 2021-10-17
什么是 A/B 测试
A/B 测试是一种随机测试,将两个不同的东西(即 A 和 B)进行假设比较。A/B 测试可以用来测试某一个变量两个不同版本的差异,一般是让 A 和 B 只有该变量不同,再测试目标对于 A 和 B 的反应差异,再判断 A 和 B 的 […]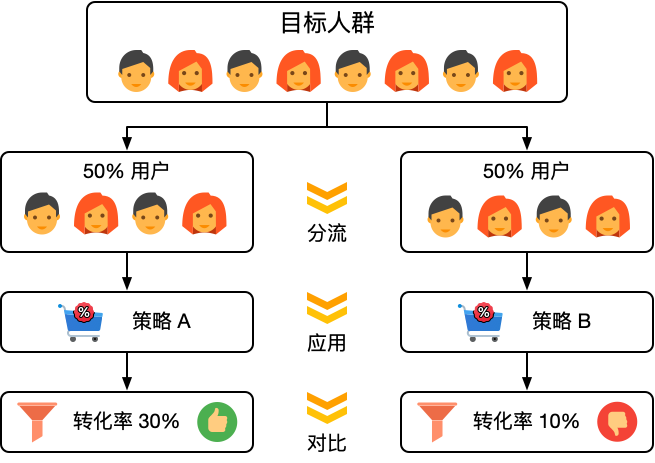
-
-
最近学习了Brinson模型,发现网上关于这方面的资料挺少,所以结合个人学习过程,总结一下如何通过R实现Brinson归因分析。
关于Brinson分析的原理不再说明,网上有一些资料,推荐大家看这个:
Brinson 绩效分解模型和应用
事实上,R里有一个pa包可以快速实现Brinson分析,也能出一些比较美观的图,但是知道的人并不太多,我也是查了很久才发现这个包,下面就说明一下这个包具体怎么使用。 […]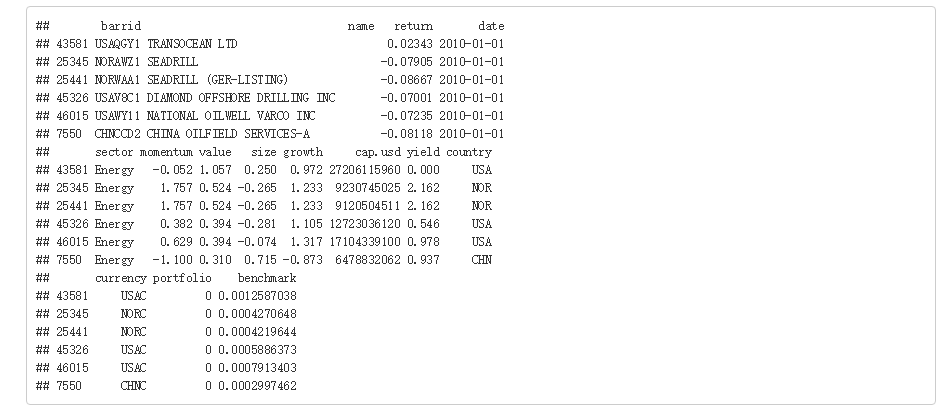
-
1. 安装SPSS
64位软件包,解压安装安装步骤即可:
链接:https://pan.baidu.com/s/1t48M16ZUdpnfWemceOQc8g
提取码:ma0a补充具体安装步骤
解压SPSS.Modeler.v18.x64.iso 得到:
打开使用说明:
根据步骤依次安装:
安 […]

-
好长时间没写东西了,前段时间一直忙着做客户满意度提升相关的工作,作为一个理论先行派,在开干之前,先了解了一下“别人家的”客户满意度评测模型,今天就把这份资料分享一下。
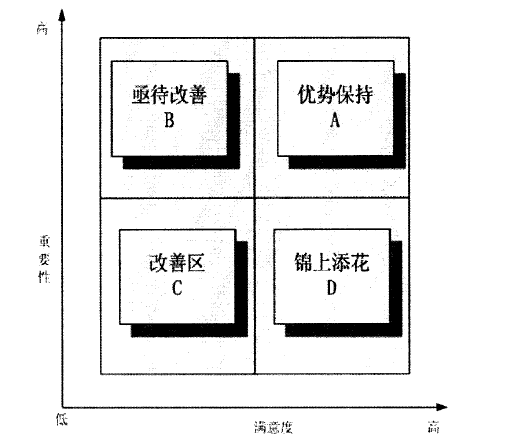
一、四分图模型四分图模型
四分图模型:偏于定性研究的诊断模型。它列出企业产品和服务的所有绩效指标,每个绩效指标有重要度和满意度两个属性,根据客户对该绩效指标的重要程度及满意程度的打分,将影响企业满意度的各个因素归进四个象限内 […]
-
、数据库瓶颈
不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。接下来就可以想象了吧(并发量、吞吐量、崩溃)。
1、IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。第二种:网络IO瓶颈,请求的数据太多,网络 […]
-
前置知识
编程语言
至少应该掌握一门编程语言,计算机专业的同学大多学的第一门编程语言是 C 语言,然后再学 Java 语言,对于零基础的同学,可直接学习 Java 语言,至少应该把 Java SE 阶段学完!计算机基础
如果你是计算机相关专业,相信你这些基础都已经会了,可以直接略过本节,往下看。但 […]
-
普华永道三年前推出了一系列机器学习图解,无奈网上流传的图都不清晰,自己从网上找到了清晰版,配合文字再整理下。
一、机器学习概览
什么是机器学习?
机器通过分析大量数据来进行学习。比如说,不需要通过编程来识别猫或人脸,它们可以通过使用图片来进行训练,从而归纳和识别特定的目标。
机器学习和人工智能的关系
机器学习是一种重在寻找数据中的模式并使用这些模式来做出预 […]
-
-
有没有面对着稀奇古怪的DAX而感到有点丈八金刚摸不着头脑或者干瞪眼?!
有没有想得到某个值想不出来DAX怎么写而直跳脚!?
看完这篇文章,你会恍然大悟,捂脸偷笑。呼呼呼~
前言:
这篇文章对于具有一点SQL查询基础人会十分容易理解,譬如:掌握SELECT,SUM,GROUP BY等。注:此文不涉及到Filter Context(筛选上下文)的介绍。
正文:
对于对SQL […]
-
作者:俊欣,链接:Python社交网络可视化
我们平常都会使用很多的社交媒体,有微信、微博、抖音等等,例如在微博上面,我们会关注某些KOL,同时自己身边的亲朋好友等等也会来关注我们自己,慢慢地随着粉丝的量不断累积,这层关系网络也会不断地壮大,很多信息也是通过这样的关系网络不断地向外传播,分析这些社交网络并且了解透彻它对于我们做出各项商业决策来说也是至关重要的。
今天我就用一些Python的第三方库来进行社交网络的可视化。 […]
- 读取更多

.png)