一、回归分析的不足
我们大家对回归分析很清楚,但是有这样一类变量,它们的因变量不是连续型变量,而是分类变量。比如这件商品是买还是不买;某个病人是否已经痊愈。这种现象是经常出现的。
我们以这件商品买和不买来进行讨论。用“1”来表示“买”,用“0”来表示“不买”。在这里,我们记“买”的概率为P(y=1),记“不买”的概率为P(y=0)。对因变量为分类变量直接拟合,实际上是拟合的发生概率。如果用之前回归分析的思路来解决这个问题应用如下方式表示:
![]()
在这里,让我们来思考一下上面回归分析的模型能否很好的分析我们的问题,答案是否定的,因为用一般的回归分析模型来对问题进行解决有以下两点不符合要求:
⑴.取值区间:上述模型右侧的取值范围是负无穷到正无穷,但是左侧的取值区间仅仅是0—1。
⑵.曲线关联:大量的实验观察,因变量P和自变量之间的关系不是简单的直线关系,而是S型曲线关系。和人口增长模型、经济增长模型的曲线类似。
二、Logistic回归
㈠.初识Logistic回归
对于上述的回归分析,我们需要对其进行改动,才能使得它能够更好地解决我们的问题,基于前面所述,等号左右的取值范围不同,因此我们需要对其中一方来进行改动,使得两边的取值区间变得相同。
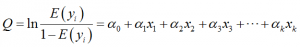
另经过上述巧妙的转换,我们可以得到因变量的表达形式为:
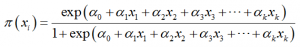
这其中,和前面线性回归分析模型中的系数类似。
㈡.Logistic回归的似然估计
在这里,我们首先将因变量用0和1来表示,那么,则给定条件下因变量的值为y=1的概率为
![]()
用同样的条件得到结果为y=0的条件概率为:
![]()
于是,我们得到
![]()
由于各个观测变量之间相互独立,则它们的联合分布可以表示为各个边际分布的乘积
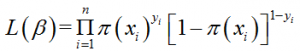
其对数似然值为:
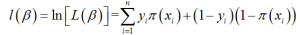
对上式可以进行最大似然估计。
㈢.Logistic回归中的一些注意事项
⑴因变量是二分类变量或者是某事件的发生概率,因此Logistic模型的因变量要服从二项分布。
⑵自变量和logit(p)之间是线性关系。
⑶残差和为0,且残差服从二项分布。
⑷各观测变量间相互独立。
误差应当是服从二项分布,而不是正态分布。
三、Logistic回归举例说明应用
有100个样本点,每个点包含有两个数值特征是x1和x2,运用Logistic回归模型拟合出最佳参数。(数据见附录)
#-*- coding: utf-8 -*-
import numpy as np
from pandas import Series, DataFrame
import pandas as pd
import math
#读取数据
def loadDataset():
dataMat=[]
labelMat=[]
fr=open(‘testSet.txt’)
for line in fr.readlines():
lineArr=line.strip().split()#用于修剪空白符或者换行符
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])#将logistic回归中的右边的回归部分的数据整理好
labelMat.append(int(lineArr[2]))#将logistics回归中的左边的0、1的数据整理好
return dataMat,labelMat
#构造之前给出的sigmoid函数
def sigmoid(x):
h=np.ones((len(x),1))
for i in range(len(x)):
h[i]=1.0/(1+math.exp(-x[i]))
return h
#运用迭代法找出最佳系数
def gradAscent (dataMatin,classLabels):
dataMatrix=np.mat(dataMatin) #转换为一个矩阵形式
labelMat=np.mat(classLabels).transpose()#矩阵的转置,变为一个列矩阵
m,n=np.shape(dataMatrix)#将矩阵dataMatix的行列表示
alpha=0.001 #目标移动的步长
maxCycles=500 #迭代的次数
weights=np.ones((n,1)) #先将权重赋值为1
for k in range(maxCycles):
dataMatrix*weights
h=sigmoid(dataMatrix*weights)
error=(labelMat-h)
weights=weights+alpha*dataMatrix.transpose()*error
return weights
#将logistic回归从图像中给出
def plotBestFit(wei):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataset()
dataArr=np.array(dataMat)
n=np.shape(dataArr)[0]
xcord1=[]
ycord1=[]
xcord2=[]
ycord2=[]
for i in range(n):
if int(labelMat[i])==1:
xcord1.append(dataArr[i,1])
ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1])
ycord2.append(dataArr[i,2])
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(xcord1,ycord1,s=30,c=’red’)
ax.scatter(xcord2,ycord2,s=30,c=’green’)
x=np.arange(-3.0,3.0,0.1)
y=((-weights[0]-weights[1]*x)/weights[2]).T #0是两个分类的分界点
ax.plot(x,y)
plt.xlabel(‘x1’)
plt.ylabel(‘x2’)
plt.show()
dataArr,labelMat=loadDataset()
weights=gradAscent(dataArr,labelMat)
print weights
plotBestFit(weights)
![]()
将其通过图像表示出:
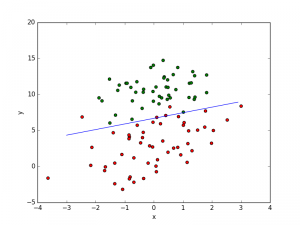
由此可以得到两个红色的点被预测错。