统计方面的3个Python包
作者|Cornellius Yudha Wijaya
编译|VK
来源|Towards Data Science
原文链接:https://towardsdatascience.com/3-top-python-packages-to-learn-statistic-for-data-scientist-d753b76e6099
众所周知,数据科学家比统计学家有更好的编程技能,比程序员有更好的统计知识。虽然学习编程技能不是一件容易的事,但有时新数据的人会忘记统计技能。
我知道统计很难学,尤其是对于那些没有受过正规统计教育的人来说。然而,在现代技术的帮助下,从零开始学习统计是可能的。
我知道如果你想学统计学,很多人会争论。你应该使用R语言而不是Python;但是,我想通过使用Python包提供另一种选择,因为许多人从学习Python语言开始他们的数据科学之旅。
在本文中,我想向你展示3个最重要的Python统计软件包,以及如何使用该软件包的示例—记住,用于学习。我们开始吧!
1.Scipy.Stats
SciPy(发音为“Sigh Pie”)是一个开源包计算工具,用于在Python环境中执行科学方法。Scipy本身也是许多数学、工程和数据研究中使用的数值算法和特定领域工具箱的集合。
Scipy中可用的API之一是名为Stats的统计API。根据Scipy的主页,Scipy.Stats是一个包含大量概率分布和统计函数库的模块,特别是概率函数。
在Scipy.Stats模块中,有许多统计函数API可供进一步学习参考。他们是:
- Continuous distributions
- Multivariate distributions
- Discrete distributions
- Summary statistics
- Frequency statistics
- Correlation functions
- Statistical tests
- Transformations
- Statistical distances
- Random variate generation
- Circular statistical functions
- Contingency table functions
- Plot-tests
- Masked statistics functions
- Univariate and multivariate kernel density estimation
为了更好地理解统计工作函数,Scipy.Stats还提供了一个可以跟随的教程。
https://docs.scipy.org/doc/scipy/reference/tutorial/stats.html
让我们尝试使用Scipy.Stats学习一些统计信息。
如果你使用的是Anaconda发行版中的Python,那么Scipy包已经内置在环境中了。如果选择独立安装Scipy,则需要安装dependence包。你可以通过pip执行下面的这一行来实现这一点。
python -m pip install --user numpy scipy matplotlib ipython jupyter pandas sympy nose
让我们学习概率分布的最简单的概念,也就是正态分布。首先,我们将必要的包导入到环境中。
# 从Scipy导入统计包
from scipy import stats
# 导入正态分布类
from scipy.stats import norm
我们引入的norm类将成为一个概率函数,产生一个服从正态分布的随机变量。为了获得更多关于这个类的信息,我们可以尝试打印文档。
print(stats.norm.__doc__)

该文档将为你提供理解对象、可用方法和类应用程序示例所需的所有基本信息。
norm类用于产生服从正态分布的随机变量。这个包已经为你提供了了解它的所有解释,你只需要执行几行代码就可以生成示例。让我们用这个例子来生成一个正态分布图。
import matplotlib.pyplot as plt
# 产生1000个服从正态分布的随机变量
r = norm.rvs(size=1000)
# 绘制分布图
fig, ax = plt.subplots(1, 1)
ax.hist(r, density=True, histtype='stepfilled', alpha=0.2)
ax.legend(loc='best', frameon=False)
plt.show()
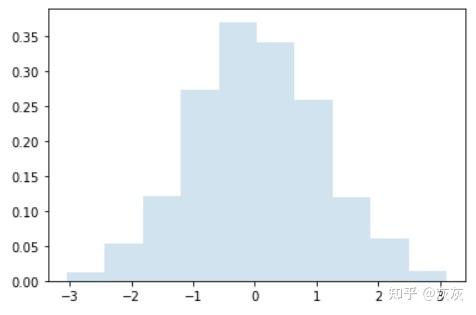
我建议你花点时间浏览一下统计教程,以理解软件包和定理。
2. Pingouin
Pingouin是一个开源的统计软件包,主要用于统计分析。这个软件包提供了许多类和函数来学习基本的统计学和假设检验。根据开发者的说法,Pingouin是为那些想要简单而详尽的统计功能的用户而设计的。
Pingouin很简单,但是很详尽,因为这个包提供了更多关于数据的解释。在Scipy.Stats上,当有时我们需要更多关于数据的解释时,它们只返回T值和p值。
在Pingouin包中,计算是在上面的几个步骤中进行的。例如,Pingouin的T检验不仅返回了T值和p值,还返回了自由度、效应大小(Cohen's d)、均值差异的95%置信区间、统计功率和检验的Bayes因子(BF10)。
目前,Pingouin包提供了一个可以用于统计测试的api函数。他们是:
- ANOVA ,T-test
- Bayesian
- Circular
- Contingency
- Correlation regression
- Distribution
- Effect sizes
- Multiple comparisons ,post-hoc tests
- Multivariate tests
- Non-parametric
- Others
- Plotting
- Power analysis
- Reliability ,consistency
PingouinAPI文档本身对于学习来说非常丰富。我浏览了这个文件,发现它真的很有用。例如,让我们研究方差分析函数。首先,你需要安装Pingouin包。
pip install pingouin
安装只需一秒钟。然后以mpg数据集为例,用Pingouin进行方差分析统计假设检验。
# 导入必要的包
import seaborn as sns
import pingouin as pg
mpg = sns.load_dataset('mpg')
pg.anova(data = mpg, dv = 'mpg', between = 'origin')

结果提供了所需的所有分数。对于结果的进一步解释,你应该参考这里的API文档:https://pingouin-stats.org/generated/pingouin.anova.html#pingouin.anova。
Pingouin教程还为你提供了使用一些学习教程:https://pingouin-stats.org/guidelines.html。其中之一是单因素方差分析。
方差分析测试教程(来源:https://pingouin-stats.org/guidelines.html#anova)
如果你想了解更多关于Pingouin软件包的信息,这里有更深入的解释:
3.Statsmodel
Statsmodels是一个统计模型python包,它提供了许多类和函数来创建统计估计。Statsmodel包以前是Scipy模块的一部分,但目前,Statsmodel包是单独开发的。
Scipy.Stats和statsmodel有什么不同?Stats模块侧重于统计定理,如概率函数和分布,而statsmodel包侧重于基于数据的统计估计。
Statsmodel提供了统计建模中常用的API。Statsmodel包将API分为3个主要模型:
- statsmodels.api提供了许多横断面模型和方法,包括回归和GLM。
- statsmodels.tsa.api提供时间序列模型和方法。
- statsmodels.formula.api,简单地说,你可以创建自己的模型。
对于想要更深入地理解统计建模的人来说,Statsmodel是一个很好的入门包。用户教程为你提供了理解统计所需的概念的深入解释。例如,下文解释了来自Statsmodel用户教程的endogenous(内生)和exogenous(外生) 术语:
这些术语的一些非正式定义如下:
endogenous :由系统内的因素引起的
exogenous :由系统外的因素引起的
内生变量指经济/计量经济模型中由该模型解释或预测的变量。http://stats.oecd.org/glossary/detail.asp?ID=794
外生变量是指出现在经济/计量经济模型中,但未被该模型解释的变量(即,这些变量按模型给出的值取值)。http://stats.oecd.org/glossary/detail.asp?ID=890
让我们尝试使用Statsmodel包进行OLS(普通最小二乘法)建模。如果你没有使用Anaconda发行版中的Python,或者还没有安装Statsmodel包,那么可以使用下面的代码行来完成。
pip install statsmodels
继续这些步骤,让我们通过导入包和数据集来开发模型。
# 导入必要的包
from sklearn.datasets import load_boston
import statsmodels.api as sm
from statsmodels.api import OLS
# 导入数据
boston = load_boston()
data = pd.DataFrame(data = boston['data'], columns = boston['feature_names'])
target = pd.Series(boston['target'])
# 开发模型
sm_lm = OLS(target, sm.add_constant(data))
result = sm_lm.fit()
result.summary()
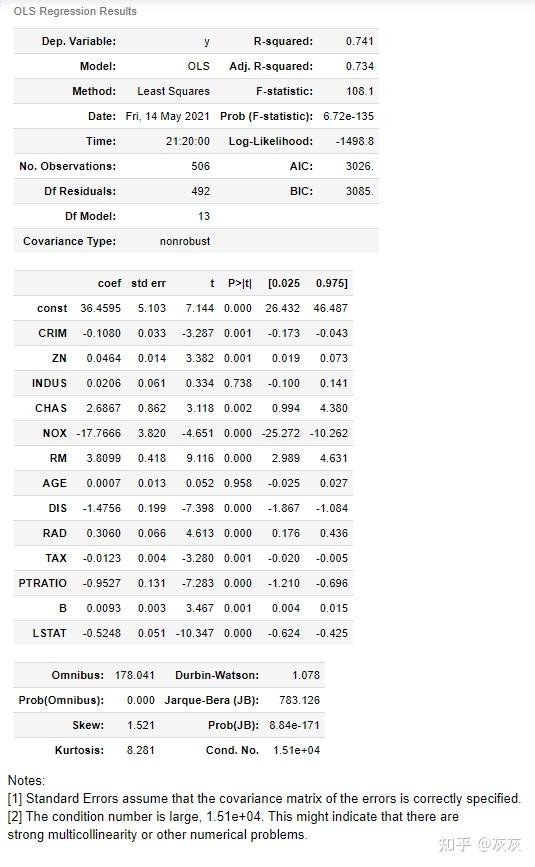
使用Statsmodel包开发的OLS模型将具有模型估计所需的所有结果。