有什么好的模型可以做高精度的时间序列预测呢?
链接:https://www.zhihu.com/question/21229371/answer/2538743651
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在刚进入时间序列领域的时候,读了很多论文,也研究了很多方法,工具。如Meta的prophet, Kats,AWS的gloun-ts, 还有像darts, sktime,pmdarima,autots等等。
其中,很多工具中都包含了很多种类的时序模型,像ARIMA, VAR, Holt-Winters, Theta等统计类模型,也有像DeepAR, LSTNet,NBeats,Transformer, Wavenet等深度学习的模型。使用下来,感触颇多。
一方面,我总是花费大力气处理数据来适配框架的要求,而这些框架到底需要什么格式的数据,真是一件伤脑经的事情!当学会了处理单变量的数据后,面对多变量的数据,又会陷入各种报错的窘境。
另一方面,各种框架均给提供了很多种模型的选择,但是这些模型都怎么用,各种参数都如何设置,就得去扒拉论文或者去wikipedia了,结果模型是不用搭建了,却成为了一个调参侠。
当然也有像autots这样的AutoML工具,首先给这个工具点个赞!它可以做到数据预处理,也内置大量的模型,可以自动化地建模。不过,这个工具也有很多令人苦恼的地方,它内置了很多模型框架,运行时打印日志十分混乱。而且搜索空间与搜索方式极其耗时和占用资源,有时候一个小问题跑了一天还没跑完,出不了结果,宕机,可能出来了还很差,真的是伤不起。
难道就没用一个工具,不用学习各种模型,也不需要我们过多的去解决数据,处理数据,什么缺失值,什么数据补齐的工作,想用arima这样简单模型就用这样模型快速建模,想用LSTM深度模型也可以马上切换,并且还可以超参数优化,将搜索过程的排名前topn自动化集成。即可以解决时序预测,也可以解决时序分类,多变量单变量,多步单步统统不用使用者来操心?
这个需求,过分吗?
老师曾说:没有什么是新的,如果找不到,那就是功夫不到。
嗯,老师说的对!
HyperTS 一款全pipeline的从数据预处理到预测评估端到端解决时间序列预测,分类,回归等问题的自动化时间序列分析工具。多模驱动,即可以选择统计模式,也可以选择深度学习,内置多种优秀的时序模型Prophet, ARIMA, VAR, DeepAR,LSTNet, NBeats等等,自动超参数调优,贪婪融合机制,多角度结果评估,可视化,这不正是在苦苦寻找的东西吗?给一个链接:
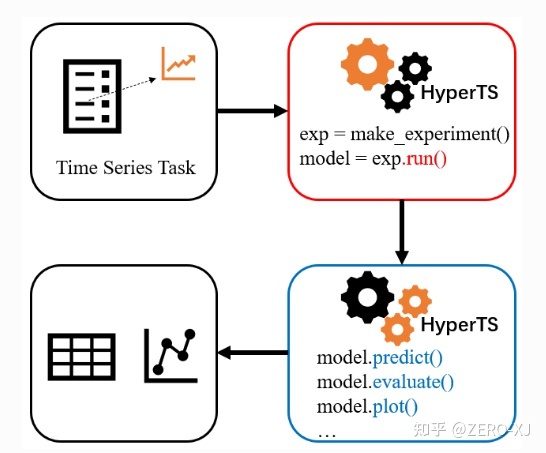

真的是轻松上手吗?
举个栗子,欢迎diss:
1、数据准备
假设现在我们手边有一个时间序列的数据,如下:
from hyperts.datasets import load_network_traffic
data = load_network_traffic()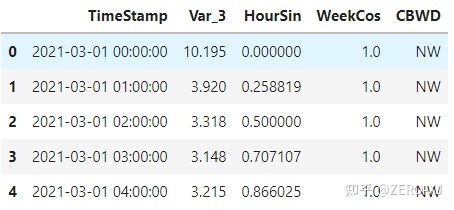
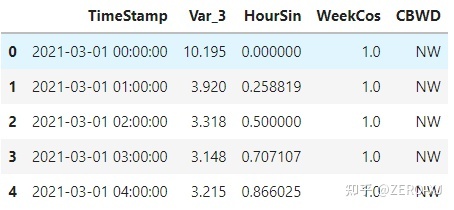
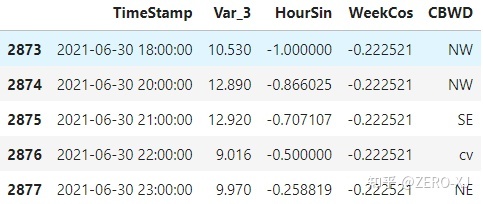
由数据我们可知:
- 时间列名称: 'TimeStamp';
- 目标列名称: 'Var_3';
- 协变量列名称: ['HourSin', 'WeekCos', 'CBWD'];
- 时间频率: 'H'.
其中,协变量既有数值型的协变量,也有类别型的协变量。
import pandas as pd
time_start = df['TimeStamp'].tolist()[0]
time_end = df['TimeStamp'].tolist()[-1]
complete_time_df = pd.date_range(start=time_start, end=time_end, freq='H')
complete_time_length = len(complete_time_df)
actual_time_length = len(df)
print('time start: {} - time end: {}'.format(time_start, time_end))
print('complete_time_length: {} - actual_time_length: {}'.format(complete_time_length, actual_time_length))
time start: 2021-03-01 00:00:00 - time end: 2021-06-30 23:00:00
complete_time_length: 2928 - actual_time_length: 2878通过计算可以看出,如果时间序列起始时间是2021-03-01 00:00:00, 结束时间是2021-06-30 23:00:00,以小时(H)为时间粒度,那么自然序列共有2928个时间点,但是实际上数据共有2878个时间点。因此,此数据在收集过程中,可能由于某些因素丢失了某些时间片段的值。
2、任务目标: 根据历史数据信息来预测未来168个时间点的信息。
对于数据集的分割,我们可以使用sklearn.model_selection内置的train_test_split的函数,这里hyperts也提供了相应的函数temporal_train_test_split供使用。
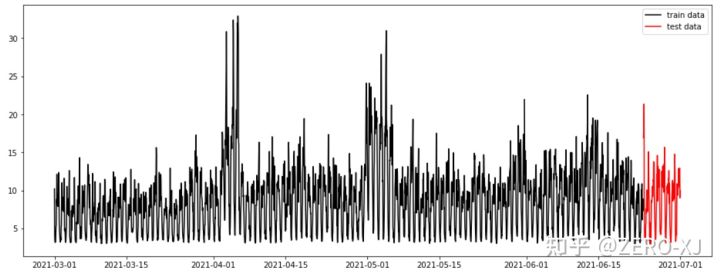
train_data, test_data = temporal_train_test_split(data, test_horizon=168)可视化任务:
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 6))
plt.plot(pd.to_datetime(train_data['TimeStamp']), train_data['Var_3'], c='k', label='train data')
plt.plot(pd.to_datetime(test_data['TimeStamp']), test_data['Var_3'], c='r', label='test data')
plt.legend()
plt.show()
3、利用HyperTS来对未来的流量变化进行预测
from hyperts import make_experiment
experiment = make_experiment(train_data=train_data.copy(),
task='forecast',
mode='stats',
timestamp='TimeStamp',
covariates=['HourSin', 'WeekCos', 'CBWD'],
ensemble_size=10,
max_trials=100,
early_stopping_rounds=10)
model = experiment.run()这里,我们从hyperts中导入make_experiment来创建实验,然后将训练数据及相关变量信息(什么任务,时间戳,协变量)告知实验。HyperTS支持了多种模式(统计模型,深度模型等)来建模,我们这里选择统计模型mode='stats'(默认)。为了搜索到更好的模型,我们通过调整参数max_trials来增加搜索的次数。同时避免陷入长时间的无效搜索,我们增加早停策略,即early_stopping_rounds限制不提升轮数。同时,我们还可以设置ensemble_size=10来进行模型集成。
更多高级特性可以参考文档https://hyperts.readthedocs.io/en/latest/
然后,运行实验搜索最佳的预测模型。
model = experiment.run()观察模型参数:
<bound method Pipeline.get_params of Pipeline(steps=[('data_preprocessing',
TSFDataPreprocessStep(covariate_cols=['HourSin', 'WeekCos',
'CBWD'],
covariate_data_clean_args={'correct_object_dtype': False,
'drop_columns': None,
'drop_constant_columns': True,
'drop_duplicated_columns': False,
'drop_idness_columns': True,
'drop_label_nan_rows': True,
'int_convert_to': 'float',
'nan_chars': None,
'reduce_mem_usage': False,
'reserve_columns': None},
covariate_data_cleaner_args={'correct_object_dtype': False},
freq='H', name='data_preprocessing',
timestamp_col=['TimeStamp'])),
('estimator',
<hyperts.hyper_ts.HyperTSEstimator object at 0x000001F0297C0278>)])>4、对于测试数据(未知数据)进行预测推理评估
X_test, y_test = model.split_X_y(test_data.copy())
forecast = model.predict(X_test)
forecast.head()
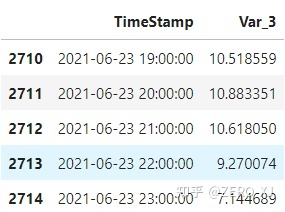
results = model.evaluate(y_true=y_test, y_pred=forecast)
results.head()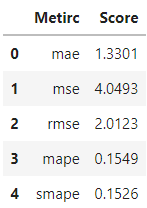

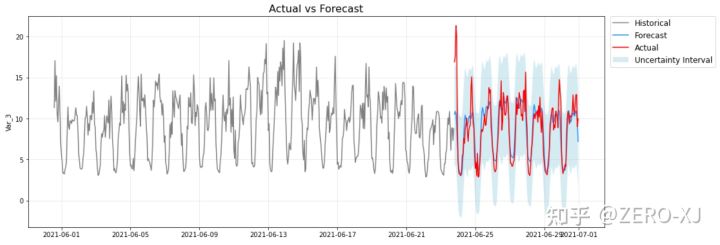
5、可视化预测曲线
HyperTS支持两种方式绘制预测曲线,一种是可互动的(需要安装plotly),一种是不可互动的(需要安装matplotlib),默认是互动的,如果想绘制非互动的,可设置参数interactive=False。
model.plot(forecast=forecast, actual=test_data, interactive=False)