Pinferencia – Serving a model with REST API
分类:Python
Pinferencia tries to be the simplest machine learning inference server ever!
Three extra lines and your model goes online.
Serving a model with REST API has never been so easy.
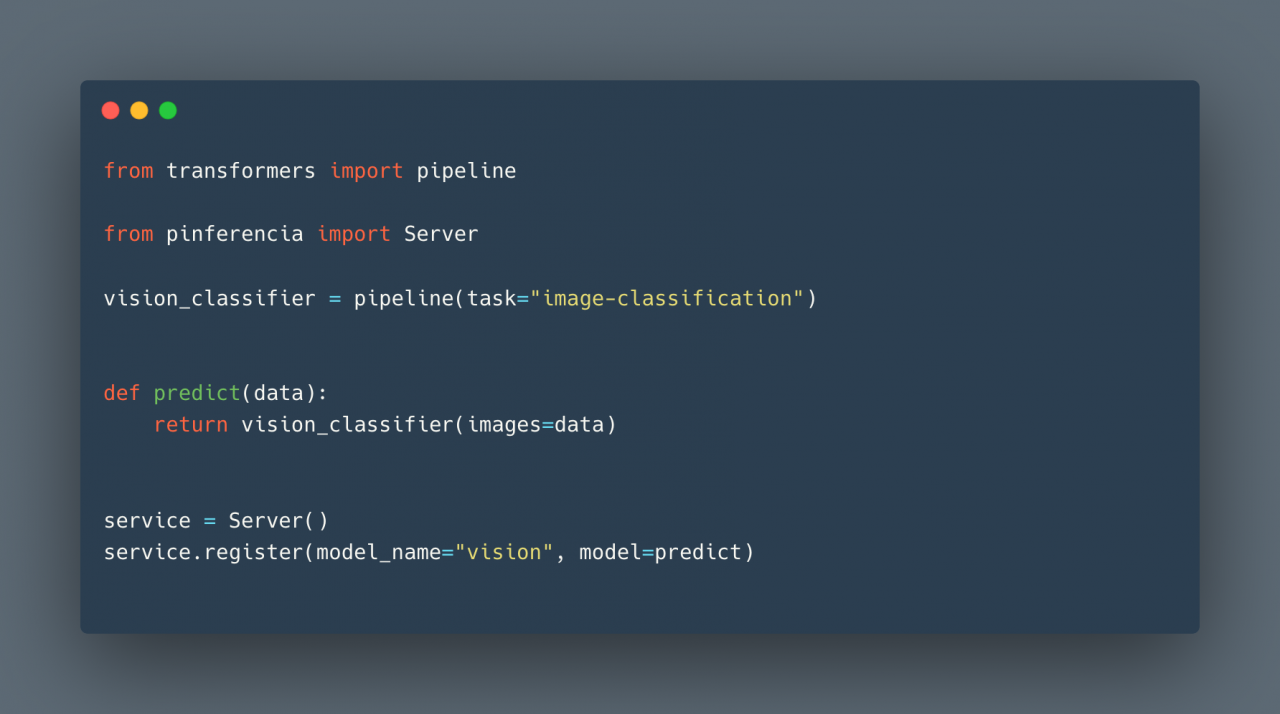
If you want to
- find a simple but robust way to serve your model
- write minimal codes while maintain controls over you service
- avoid any heavy-weight solutions
- compatible with other tools/platforms
You're at the right place.
Features
Pinferencia features include:
- Fast to code, fast to go alive. Minimal codes needed, minimal transformation needed. Just based on what you have.
- 100% Test Coverage: Both statement and branch coverages, no kidding. Have you ever known any model serving tool so seriously tested?
- Easy to use, easy to understand.
- Automatic API documentation page. All API explained in details with online try-out feature.
- Serve any model, even a single function can be served.
- Support Kserve API, compatible with Kubeflow, TF Serving, Triton and TorchServe. There is no pain switching to or from them, and Pinferencia is much faster for prototyping!
Install
pip install "pinferencia[uvicorn]"
Quick Start
Serve Any Model
from pinferencia import Server
class MyModel:
def predict(self, data):
return sum(data)
model = MyModel()
service = Server()
service.register(model_name="mymodel", model=model, entrypoint="predict")
Just run:
uvicorn app:service --reload
Hooray, your service is alive. Go to http://127.0.0.1:8000/ and have fun.