SQL学习中的一些问题
1. select的执行顺序,比如很复杂的语句,有group by和order by的时候
例如有个语句:
select name, sum(sales)
from store
group by (name)
order by name
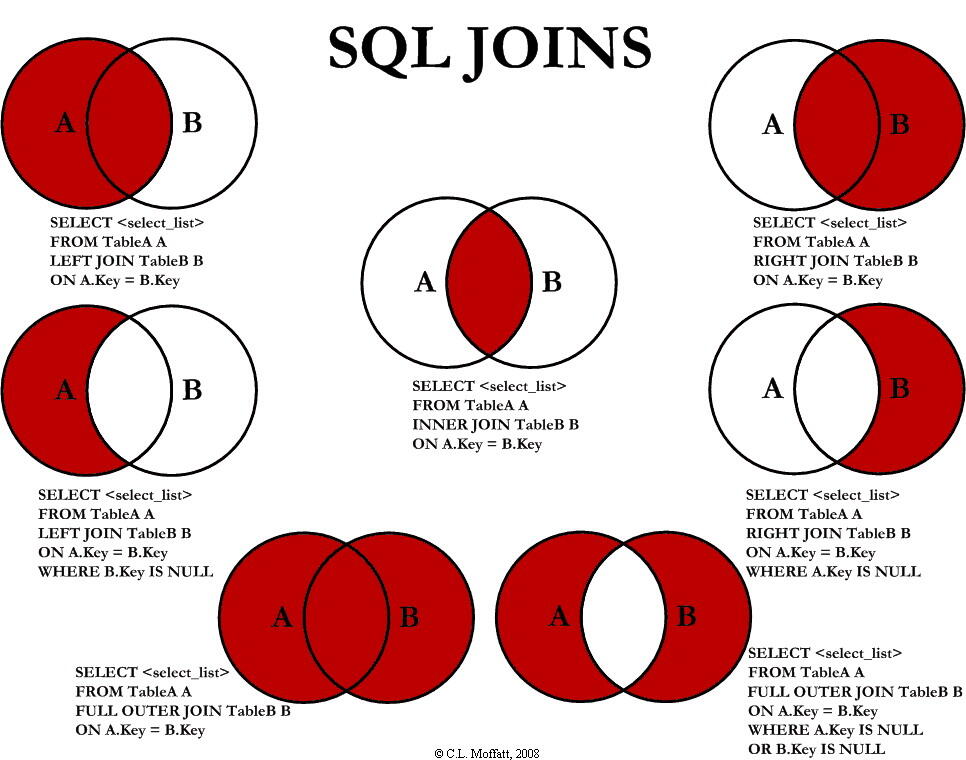
2. 表连接的几个要怎么区分?(left \right\inner join ,union ,union all) 内部连接和外部连接的区别?
3. 什么时候用group by ?
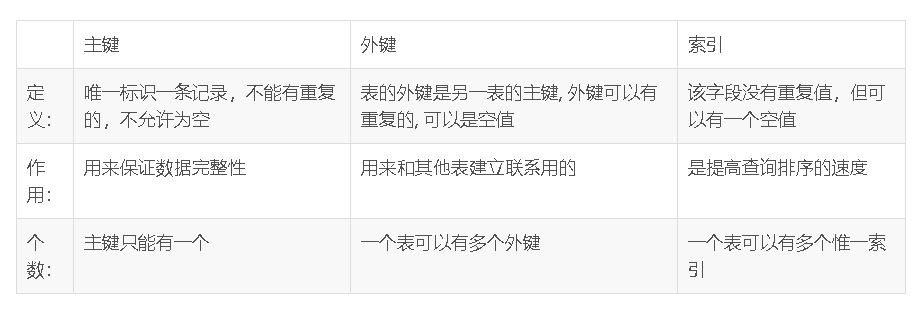
4. 主键和外来键有什么区别,具体应在哪些情况下使用?(主键是唯一的,但是为什么又说主键可以包含一个或多个列)
5. having和where有什么区别,应用场景是什么样的?
6个回复
-
 xsmile
xsmile执行顺序可以参考: https://www.cnblogs.com/rollenholt/p/3776923.html
MySQL的语句一共分为11步,如下图所标注的那样,最先执行的总是FROM操作,最后执行的是LIMIT操作。其中每一个操作都会产生一张虚拟的表,这个虚拟的表作为一个处理的输入,只是这些虚拟的表对用户来说是透明的,但是只有最后一个虚拟的表才会被作为结果返回。如果没有在语句中指定某一个子句,那么将会跳过相应的步骤。

下面我们来具体分析一下查询处理的每一个阶段
- FORM: 对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
- ON: 对虚表VT1进行ON筛选,只有那些符合<join-condition>的行才会被记录在虚表VT2中。
- JOIN: 如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3, rug from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止。
- WHERE: 对虚拟表VT3进行WHERE条件过滤。只有符合<where-condition>的记录才会被插入到虚拟表VT4中。
- GROUP BY: 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5.
- CUBE | ROLLUP: 对表VT5进行cube或者rollup操作,产生表VT6.
- HAVING: 对虚拟表VT6应用having过滤,只有符合<having-condition>的记录才会被 插入到虚拟表VT7中。
- SELECT: 执行select操作,选择指定的列,插入到虚拟表VT8中。
- DISTINCT: 对VT8中的记录进行去重。产生虚拟表VT9.
- ORDER BY: 将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10.
- LIMIT:取出指定行的记录,产生虚拟表VT11, 并将结果返回。
3年前 我来评论 -
xsmile
写的顺序:select ... from... where.... group by... having... order by.. limit [offset,]
(rows)
执行顺序:from... where...group by... having.... select ... order by... limit3年前 我来评论 -
-
-
xsmile
主键和外键参考
https://www.cnblogs.com/buptlyn/p/4555206.html
1 什么是主键 外键
学生表(学号,姓名,性别,班级) 学号是一个主键
课程表(课程号,课程名,学分) 课程号是一个主键
成绩表(学号,课程号,成绩) 学号和课程号的属性组构成一个主键
成绩表中的学号不是成绩表的主键,不过是学生表的主键,成绩表的外键,同理课程号也是成绩表的外键
定义:如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键
以一个关系的外键作主关键字的表被称为主表,具有此外键的表被称为主表的从表
2 外键的作用
外键用于保持数据一致性,完整性
主要目的是控制存储在外键表中的数据
3 主键的设计原则
1)主键应当是对用户没有意义的
2)主键应该是单列的,以提高连接和筛选操作的效率
复合键的使用通常出于两点考虑:
a)主键应当具有意义-----这为认为的破坏数据库提供了方便
b)在描述多对多关系的连接表中可以使用两个外部键作为主键------该表可能成为其他从表的主表,并成为从表的主键的一部分,使得之后的从表包含更多的列
3)永远不要更新主键
4)主键不应该包含动态变化的数据(时间戳等)
5)主键应当由计算机自动生成
4 数据库主键选取策略
建立数据库的时候,需要为每张表指定一个主键(一个表只能有一个主键,但是可以有多个候选索引)
常见的主键选取方式有:
1)自动增长型字段
自动增长型主键会省略很多繁琐的工作,但在数据缓冲模式下,不能预先填写主键与外键的值
Order(OrderID,OrderDate) //主键OrderID是自动增长型字段
OrderDetail(OrderID,LineNum,ProductID,Price)
如果要在Order表中插入一条记录,在OrderDetail表中插入若干条记录,为了能在OrderDetail表中插入正确的OrderID字段,必须先更新Order表以获得系统系统分配的OrderID,但是为了确保数据一致性,Order表和OrderDetail表必须在事务保护下同时进行更新,这显然是矛盾的
除此之外,当需要在多个数据库之间进行数据复制时,自动增长型字段可能造成主键冲突
2)手动增长型字段
3)使用UniqueIdentifier SQL Server提供一个UniqueIdentifier数据类型(16字节),并提供一个生成函数NEWID(),生成一个唯一的UniqueIdentifier
4)使用COMB类型
保留UniqueIdentifier的前10字节,后6字节表示生成时间
-------------------------------------------------------------------------------------------------------------------------------------------------------------
1 外键
外键(FK)是用于建立或加强两个表数据之间的链接的一列或多列。
通过将表中主键值的一列或多列添加到另一个表中,可创建两个表之间的连接,这个列就成为第二个表的外键
FK约束的目的是控制存储在外表中的数据,同时可以控制对主键表中数据的修改
例如:publishers表中记录出版商的信息,titles表中记录书的信息,如果在publishers的表中删除一个出版商,而这个出版商的ID在titles表中记录书的信息时被使用了,则这两个表之间关联的完整性将被破坏,即titles表中该出版商的书籍因为与publisher表中的数据没有链接而变的孤立。
FK约束可以防止这种情况的发生,如果主键表中数据的更改使得与外键表中数据的链接失效,则这种更改是不能实现的;如果试图删除主键表中的行或试图修改主键值,而该主键值与另一个表的FK约束值相关,则该操作不可实现。若要成功的更改或删除FK约束的行,可以现在外键表中删除外键数据或更改外键数据,然后将外键连接到不同的主键数据上去
外键主要是用来控制数据库中的数据完整性的,当对一个表的数据进行操作时,和他有关联的一个表或多个表的数据能够同时发生改变
例子:
A(a,b) :a为主键,b为外键(来自于B.b)
B(b,c,d) :b为主键
A中的b字段要么为空,要么为B表中存在的b值
 3年前 我来评论
3年前 我来评论 -
xsmile
参考: https://zhidao.baidu.com/question/262780155.html
1.类型:
“Where”是一个约束声明,在查询数据库的结果返回之前对数据库中的查询条件进行约束,即在结果返回之前起作用,且where后面不能使用“聚合函数”;
“Having”是一个过滤声明,所谓过滤是在查询数据库的结果返回之后进行过滤,即在结果返回之后起作用,并且having后面可以使用“聚合函数”。
2.使用的角度:
where后面之所以不能使用聚合函数是因为where的执行顺序在聚合函数之前,
如下面这个sql语句:select sum(score) from student group by student.sex where sum(student.age)>100;
having既然是对查出来的结果进行过滤,那么就不能对没有查出来的值使用having,
如下面这个sql语句: select student.id,student.name from student having student.score >90;
3年前 我来评论