
原创:金小贝 QQ交流:675229288
iris <- iris
用来描述变量的形态,对于一个样本,以每个变量的值作为不同的维度,以点的形式反映数据形态和关系,并展现在二维平面。可以描述连续变量间,或者连续变量与分类变量间的关系。核心函数plot()
plot(iris$Sepal.Length) #一个变量
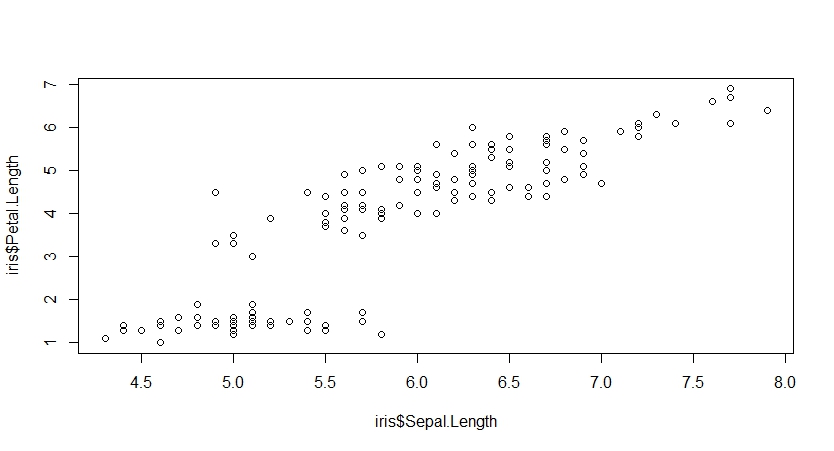
plot(iris$Sepal.Length,iris$Petal.Length) #两个连续变量,常用
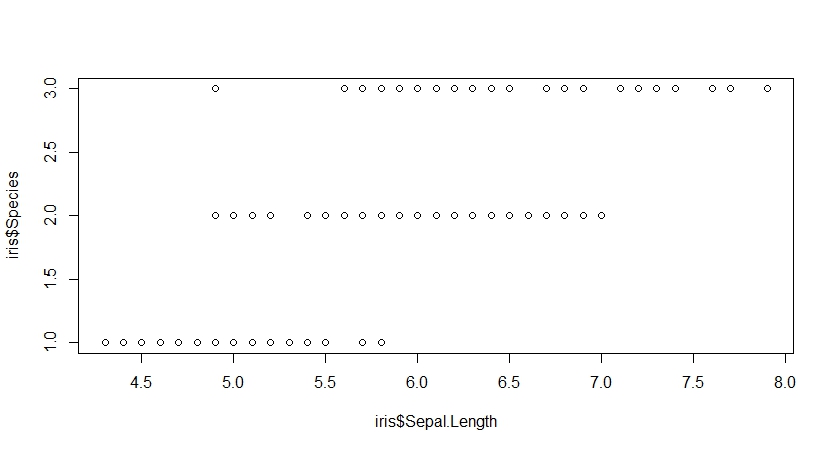
plot(iris$Sepal.Length,iris$Petal.Length) #两个变量,横轴为连续变量,纵轴为分类变量
两个连续变量则相对常用,能反映出变量的相关关系,如上图中Sepal.Length与Petal.Length目测具有正相关关系,具体衡量值可以参考上一篇的相关系数函数cor()。
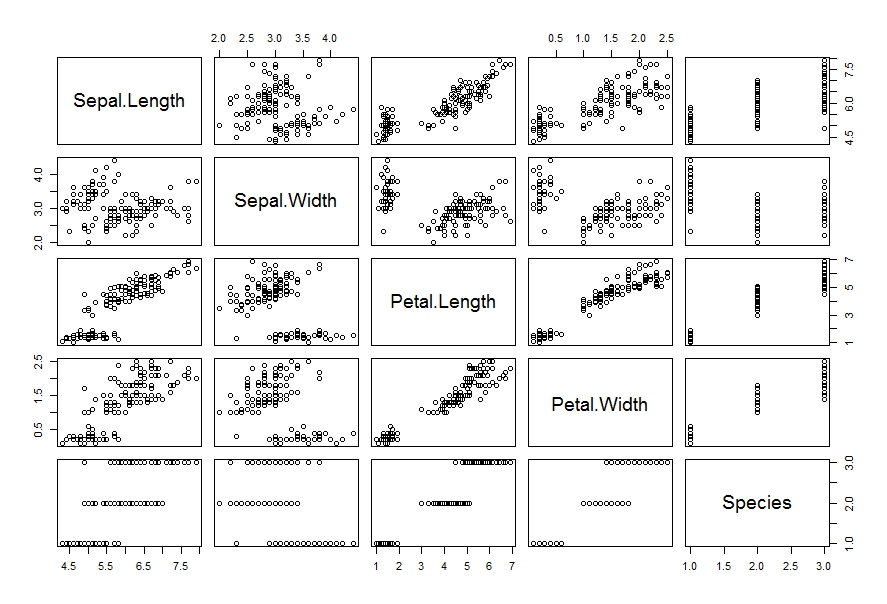
一个连续变量,一个分类变量可以观察不同分类下的值情况,如横坐标为连续变量,纵坐标为分类变量时,可以看出每一个分类变量下样本的分布状态,如上图可以观察得出因子水平为3的样本要高于因子水平2,因子水平2的样本要高于因子水平1,同时因子水平3中有一个离群点。矩阵散点图直接呈现出所有变量间两两散点图,简单高效的全盘掌握,此图可理解从一定空间程度上是对称的。
补充:plot函数里用参数type控制点之间连接的线,可以将散点图转换为折线图,如下

二、直方图
直方图又叫质量分布图,横轴为分组数据值,默认纵轴为频数,用高低柱状图反映不同分组区间样本出现的次数,由此反映数据的分布情况。直方图主要对单变量进行分析。核心函数hist()
hist(iris$Sepal.Length) #质量分布图,纵轴默认频数
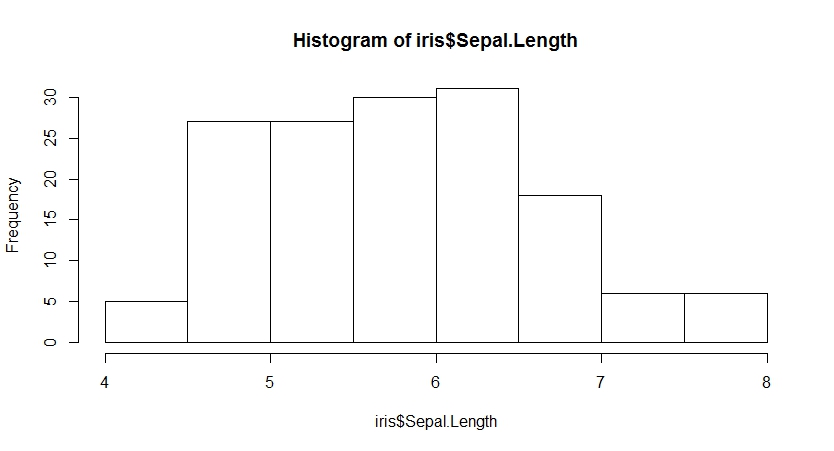
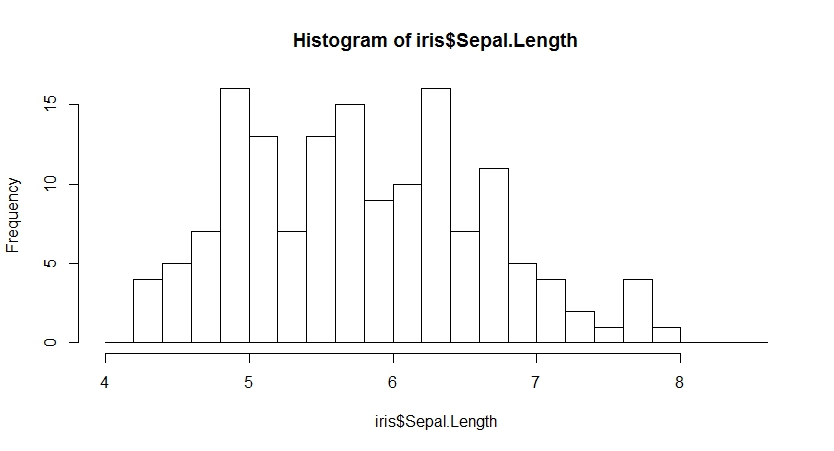
通过freq参数控制可以改变纵轴频数为概率密度,并增加概率密度曲线,此时图形面积和为1
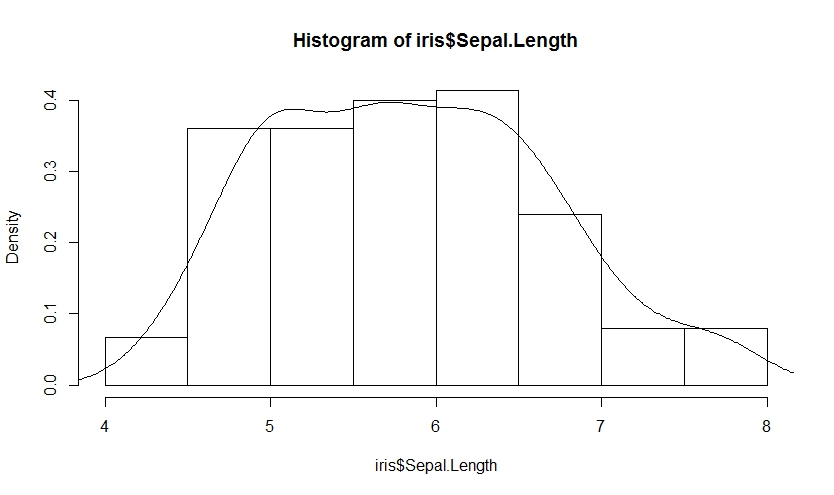
思考:hist()有个density参数,是否可以直接画出密度图或者线?
三、箱线图
箱线图是很实用、简单,但信息量很高且高效的数据探索图,用五个主要分位点描述数据情况。因为其可应用于多变量,所以不仅能一目了然整个数据分布于构成情况,便于单变量的理解(特别是异常点的判断),而且可以多变量对比。
箱线图如下,五个重要点分别为:下限点(离Q1-1.5IQR最近的正常点)、1/4分位数Q1、中位数、3/4分位数Q3、上限点(离Q3+1.5IQR最近的正常点),其中IQR为四分位差Q3-Q1,上限和下限以外的点都视为异常点(到底是温和异常点还是极端异常点这里不做进一步讨论)。
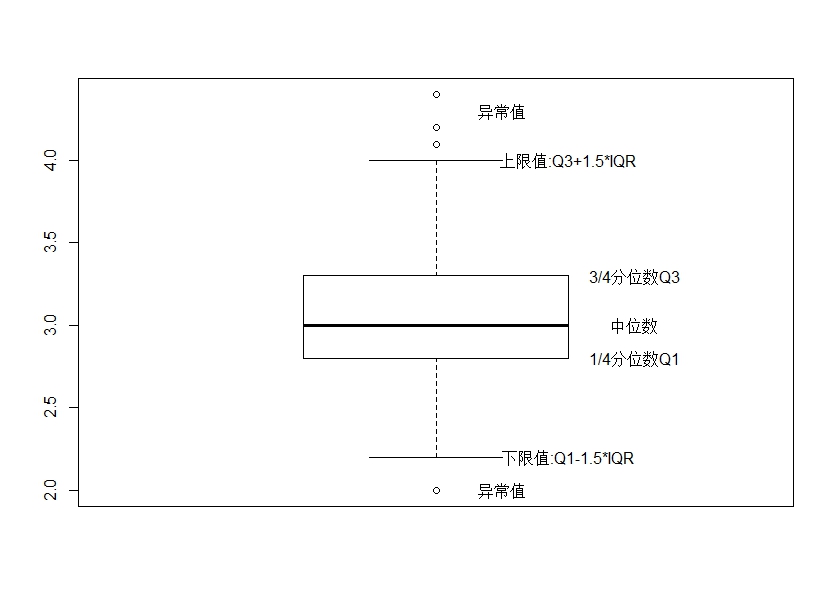
在R中实现箱线图的核心函数是boxplot()
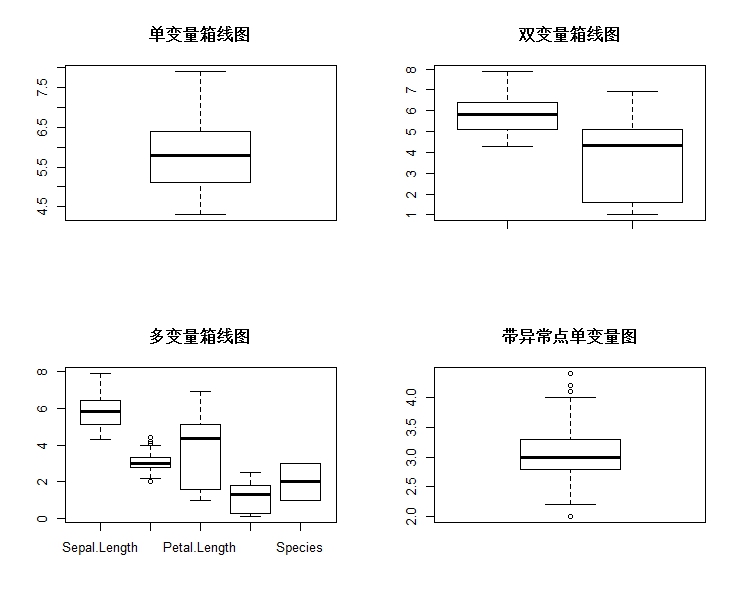
解读:如图1对于单变量能直接得出以下初步结论,Sepal.Length指标分布中位线(粗黑线条)更靠近下限,数据更集中在较小值,也可以理解为数据右偏。图2对于双变量明显可以看出Sepal.Length与Petal.Length的比较,前者各分布值均高于后者,后者中位线更靠近上限,可理解其有左偏可能(Petal.Length其实并不是简单左偏,是双峰构成,可自行通过其他方式验证)。直接将数据集作图boxplot(iris)可得出各个变量的对比情况,包括有异常点的变量有哪些?同时看到Species作为分类变量只有1、2、3三个水平。最后单独拿出Sepal.Width作图可以看到有4个离群点,反映出数据相对分散,个别点可能为异常点,在分析和处理的时候需要注意。
重点补充:分类变量与连续变量的交叉探索:更多时候探索不同分类下的相同指标更具实际意义。
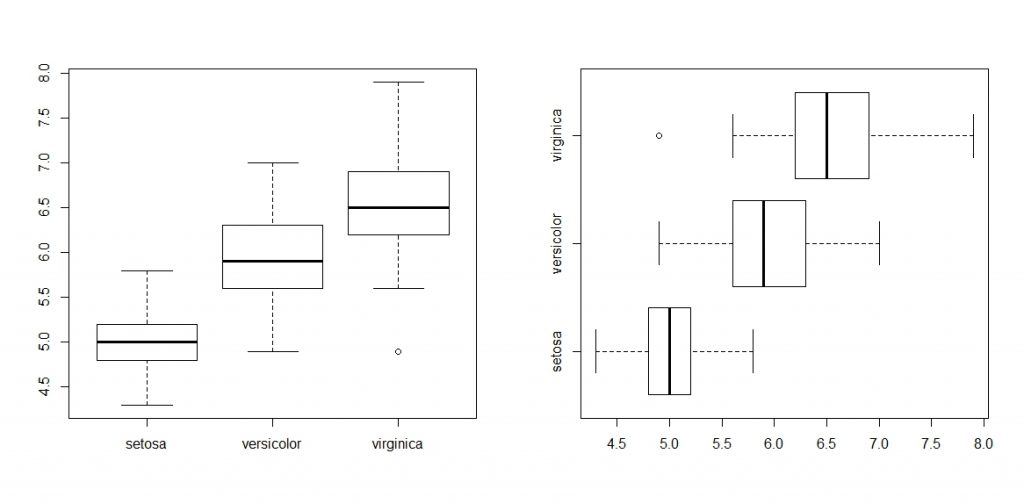
另外,图形也有详细的信息供查看,首先把图形赋值,然后使用str函数:
其中stats的五个数依次为五个重要分位点:下限点、Q1、中位数、Q3、上限点,n为样本个数,out代表离群点。
四、柱状图与饼图
对于分类变量的探索,以上通过箱线图可以对比其分位点,大概了解概貌,也可以通过柱状图(条形图)或饼图对其进一步把握。柱状图通过高低柱直观反映分类(或时序)绝对数量,可应用于单变量和多变量,饼图则更直观的以面积的形式展示分类数据的大小(或比例)。
先准备示例数据,分别为根据变量Species分类的Sepal.Length和Sepal.Width的均值:
作柱状图(条形图):
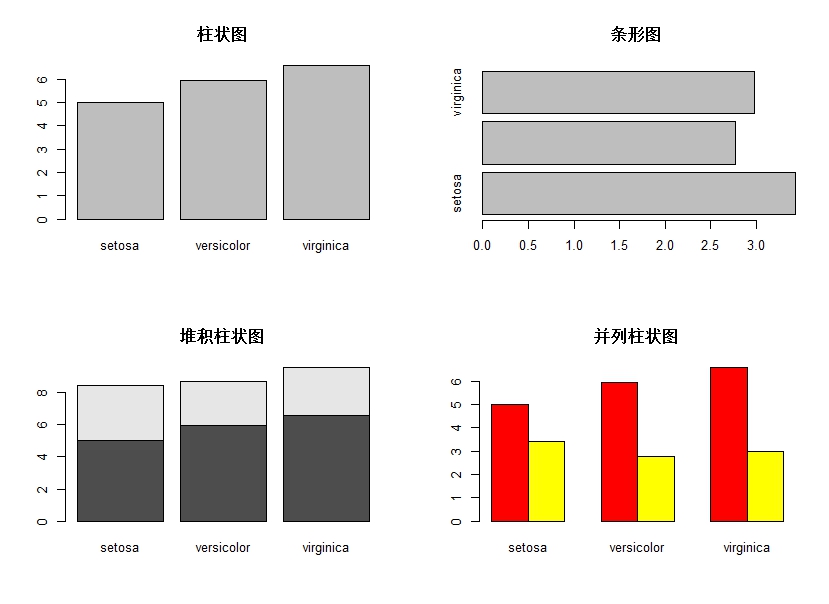
解读:柱状图显示了不同分类下Sepal.Length均值对比,barplot函数中通过horiz参数设置为TRUE将柱状图转换为条形图,条形图反映的是Sepal.Width的均值对比。当有几列数据时默认为堆积柱状图,可通过修改beside参数为TRUE设置图形显示为并列柱状图。同样条形图也可以多变量,通过设置beside函数进行堆积和并列转换,可自行尝试。
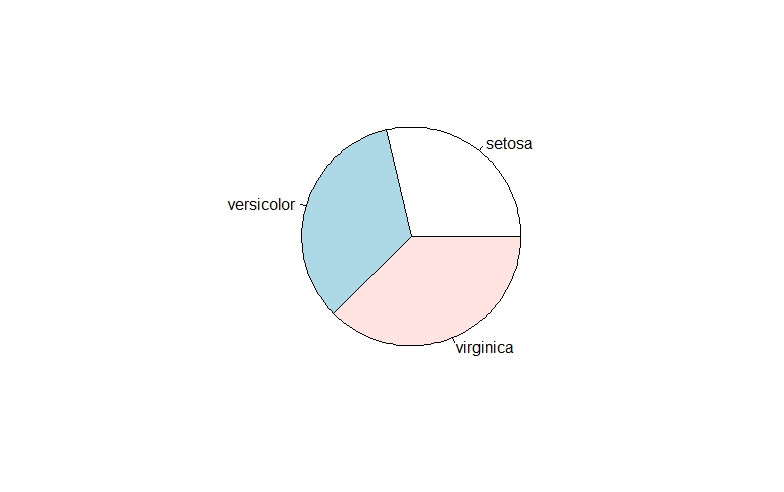
饼图与柱状图表达的信息基本一致,都是不同类之间的对比,本人并不推荐饼图,现在使用越来越少,可能有些人比较情有独钟,此处仅列出做参考,核心函数pie()
pie(SL) #饼图
五、相关系数矩阵图
另一个很实用的是相关关系的图形化展现,即将cor实现的相关系数矩阵可视化,特别是在变量较多时用肉眼去观察数字是很费时且不靠谱的。核心函数corrplot()
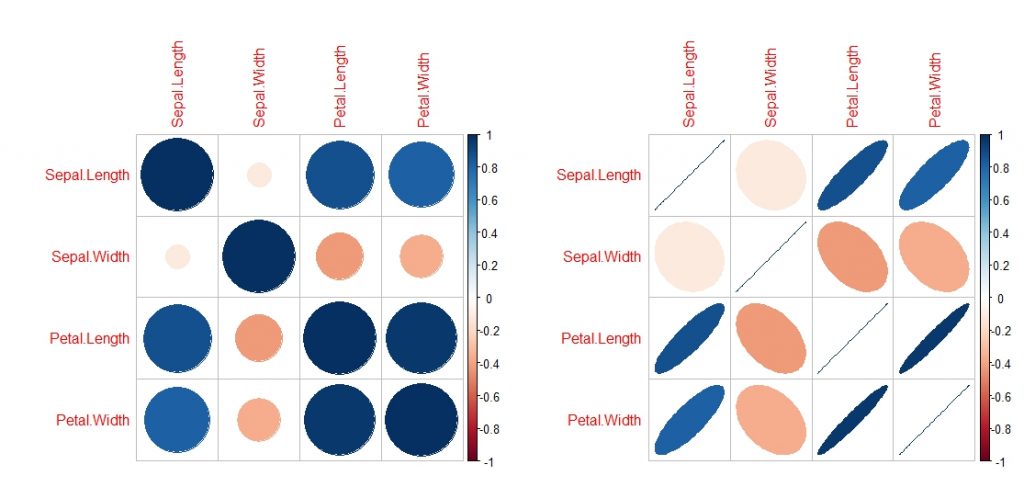
解读:corrplot()需要先得到相关系数矩阵,首先将iris数据集的1到4列变量的相关系数矩阵赋值给cor,用()括起命令实现了执行语句后直接在控制台显示结果。corrplot(cor)生成左图(默认为圆形),圆的大小及颜色代表不同的结果,直径越大、颜色越深表示相关系数越高,默认冷色系代表正相关,暖色系代表负相关。参数method调整为ellipse则用椭圆表示,椭圆越扁、颜色越深表示相关系数越高,如右图中变量自身的相关系数为1则椭圆扁成了一条线,ellipse时除了用颜色冷暖区分正负相关外,椭圆方向也代表了正负相关情况,请自行揣摩。另外method还有其他可以设置,如pie、number等。
图形展现,双目所及,沉淀于心,灵动于脑,准确的数据把握才能让数据处理、分析、挖据更加得心应手、游刃有余。