原创:金小贝 QQ交流:675229288
数据分析的步骤中,我们公认的“数据整理”是很重要的一步,“数据整理”后的数据质量直接影响分析和建模的结果,而且这步也是最耗时、耗精力的一步,一般60%-80%的时间或精力都在整理数据。
而“数据整理”过程其实也是“数据探索”的过程,甚至此时已经进入了初步分析过程,有人叫它为“探索性数据分析”。在真正开始处理数据前,对数据整体及细节的全方位把握确实是相当重要的。无论是生活还是工作,不能像无头苍蝇一样四处乱撞,要善于利用自己的头脑全局和细节的把握数据,因为你是数据分析师!
数据探索可以从两方面看,一是抽象的数字型探索(结果展示都是数据,需要一定的统计学基础知识辅助理解),二是直观的可视化探索(结果以各种图的形式展现)。本篇主要介绍数字型探索,数据以iris数据集为例(R自带的datasets包中提供了上百个数据集可供练习使用)。
一、查看自带数据集
data() #调出datasets包中自带数据集
dim(data()$results) #查看数据集个数
iris <- iris #将iris数据集导入到内存
iris
解读:首先调出datasets包自带数据集,查看了数据集的个数104个,然后将iris数据集导入内存,赋给一个叫iris的数据框(当然也可以叫其他名字)。千呼万唤始出来,最后看到美丽iris真面目:5个变量,但是记录数很多很多,几乎刷屏了,一下蒙了的感觉有木有?实际情况下可能有更加错综复杂的数据,几十个变量,几万、几十万、甚至百万条数据记录,如何解?
二、显示部分内容
head(iris) #前6行
head(iris, 10) #前10行
tail(iris) #后6行
tail(iris, 3) #后3行
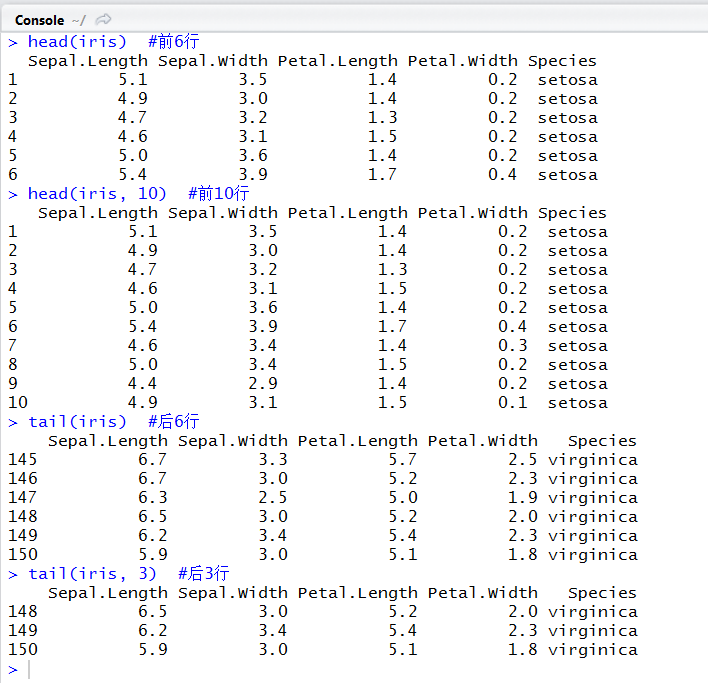
解读:分别抽取开始(head)和末尾(tail)记录,并通过参数控制显示记录条数,来局部观察数据情况。仍无法看到iris的全貌,只看到了片花寸叶。
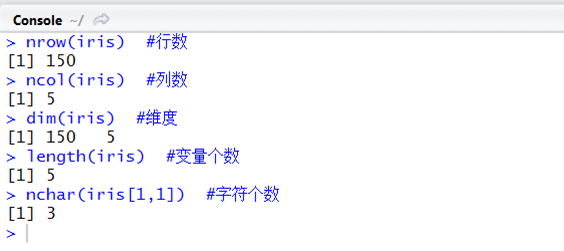
三、数据维度
nrow(iris) #行数
ncol(iris) #列数
dim(iris) #维度
length(iris) #变量个数
nchar(iris[1,1]) #字符个数
解读:共150条记录,5个变量,本数据框是150 × 5 ,第一个元素是3个字符长度(5.1)。虽然dim一个函数即可解决行和列,但在以后编程过程中会经常使用nrow和ncol。另外length与nchar还需要多多揣摩。到此为止美丽的iris高矮胖瘦我们知道了。
四、总体概况
class(iris) #对象类型
str(iris) #数据结构
summary(iris) #数据摘要
attributes(iris) #数据属性。因为会列出行名称,所以数据量少时使用
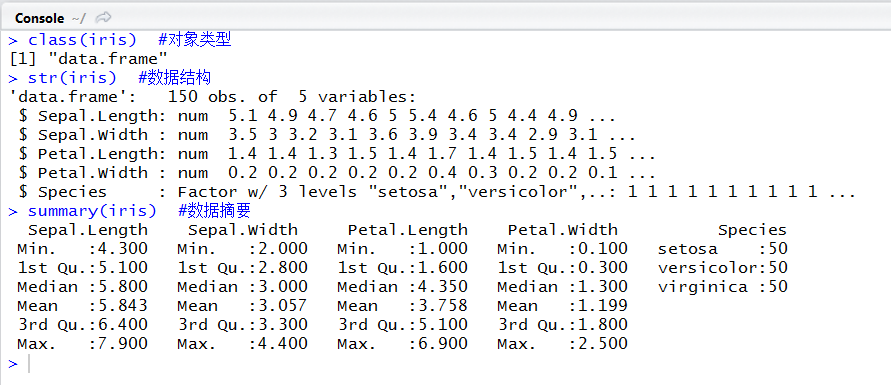
解读:class是判断对象类型的函数,iris为data.frame(数据框)。str和summary是最常用的反应对象整体情况的函数,从str结果看出对象类型为data.frame,150个观测记录,5个变量,前4个变量均为数值型(numeric),最后一个是因子型(factor)且有三个值。summary结果更加丰富,每个数值型变量依次为最小值、1/4分位数、中位数(1/2分位数)、平均值、3/4分位数、最大值,因子型变量则显示因子值及对应记录条数。attributes不做展开讲解,自行实验,主要信息等同于names和class。至此这朵美丽的鸢尾花我们有个基本的了解。
 请独自思考一下中位数与均值的关系,有些均值大于中位数,有些小于,初步判断这说明什么?
请独自思考一下中位数与均值的关系,有些均值大于中位数,有些小于,初步判断这说明什么?
 推荐一 describe函数
推荐一 describe函数
describe(iris) #数据描述,需要加载Hmisc包
install.packages(‘Hmisc’) #安装Hmisc包
library(Hmisc) #加载Hmisc包

解读:需要加载Hmisc包,首次需要安装install.packages(‘Hmisc’)。此函数显示信息更加丰富,具体解读如下:对象包含5个变量,150个观测记录。第一个变量Sepal.Length包含150个值,0个缺失值,35个唯一值,均值、各个主要分位数,5个最小值及5个最大值,其他类似。因子型变量Species有150个值,0个缺失值,3个唯一值,分别为setosa、versicolor、virginica,均为50个,占比均为33%。
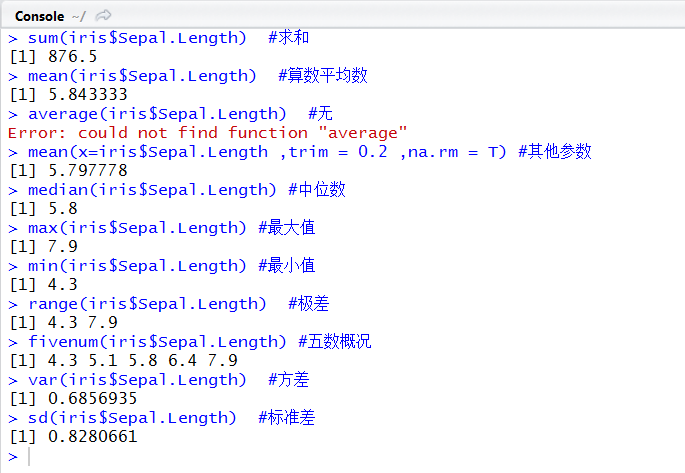
五、统计数据
连续型变量有基本的统计指标,以指标Sepal.Length为例
sum(iris$Sepal.Length) #求和
mean(iris$Sepal.Length) #算数平均数,没有average()
mean(x=iris$Sepal.Length ,trim = 0.2 ,na.rm = T) #其他参数
median(iris$Sepal.Length) #中位数
max(iris$Sepal.Length) #最大值
min(iris$Sepal.Length) #最小值
range(iris$Sepal.Length) #极差
fivenum(iris$Sepal.Length) #五数概况
var(iris$Sepal.Length) #方差
sd(iris$Sepal.Length) #标准差
解读:单独函数计算各类统计指标。主要注意的是mean函数可以通过参数扩展求平均值,五数概况fivenum分别为最小值、1/4分位数、中位数、3/4分位数、最大值,方差和标准差都是反映数据的离散程度,越接近均值方差越小,标准差为方差开方即得。
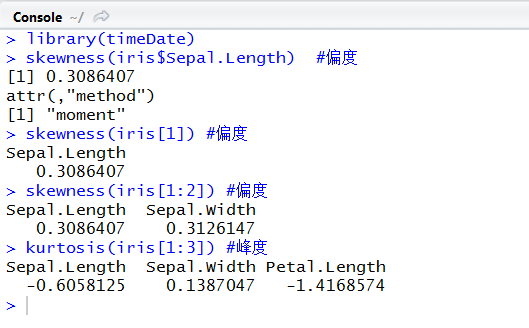
library(timeDate)
skewness(iris$Sepal.Length) #偏度
skewness(iris[1]) #偏度
skewness(iris[1:2]) #偏度
kurtosis(iris[1:3]) #峰度
解读:加载timeDate包,调用skewness函数计算偏度,kurtosis函数计算峰度。无论偏度还是峰度都是和正态分布对比,即与正态分布的偏离程度。用的较多的为偏度值,正态分布的偏度值为0,大于0表示右偏,峰值在左,长尾在右,右边有很多极值存在,小于0则表示左偏,实际应用中偏度值在[-1,1]之间一般可以认为无偏。峰度值反应了陡峭程度,正态分布峰度值为0,大于0表示尖峰,小于0表示平峰。
回答刚才的独立思考的问题,一般讲如果均值mean>中位数median,则数据呈右拖尾,右边极值导致均值在中位数右侧,从偏度的角度即为右偏(正偏),skewness>0。
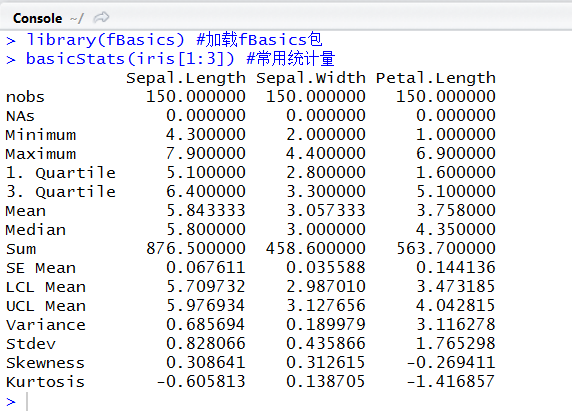
推荐二 basicStats函数
library(fBasics) #加载fBasics包
basicStats(iris[1:3]) #常用统计量
解读:分别给出各个指标的基础信息和常用统计量,也可以比较全面的展现数据信息。nobs为观测值个数,NAs为缺失值个数,SE Mean为标准误均值,UCL\LCL Mean为95%置信水平下均值的上下限,Variance与Stdev为方差和标准差。
六、其他
在实际应用中,个人觉得以下函数也需要掌握
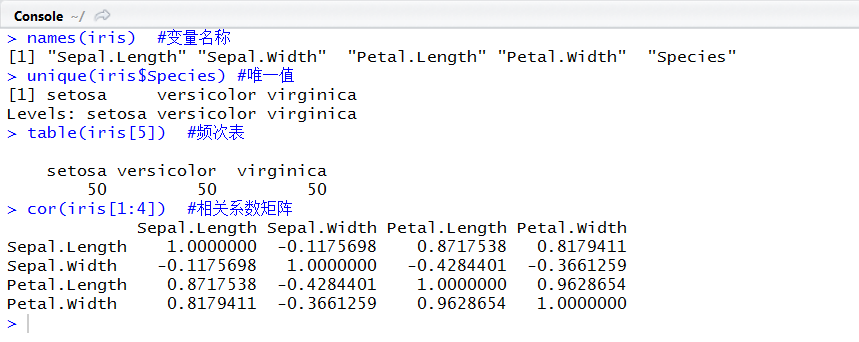
names(iris) #变量名称
unique(iris$Species) #唯一值
table(iris[5]) #频次表
cor(iris[1:4]) #相关系数矩阵
解读:names可以返回变量名称,如果需要修改变量名称,也是names函数完成。unique返回唯一值,额外可以达到数据去重的目的。table简单的形成一个频次表,可见每一类都是50个,简单实用。cor可以简单判断指标见得相关关系(分为±相关,越接近于1越正相关,越接近-1越负相关),生成相关系数矩阵,Petal.Width与Petal.Length高度相关,相关系数为0.96。
complete.cases(iris) #判断是否完整,返回逻辑值
is.na(iris) #判断是否NA,返回逻辑值
sum(complete.cases(iris)) #得出完整记录个数
sum(is.na(iris)) #得出缺失值个数
解读:complete.cases与is.na是对反义词,前者判断是否完整,后者判断是否是NA,用sum得出逻辑值为TRUE的数量则得到没有缺失值的案例个数,或者是有NA值的案例个数。
通过以上过程,已经比较全面的探索了数据基本信息,至此鸢尾花彻底绽放了。因人而异,可有选择性的使用适合自己的方式方法,达到目的即可。
附:iris 鸢(yuān)尾花
花语:优美的心,绝望的爱



[/强]写的很详细,R是很容易上手的。
编者是牛人啊,我现在也在学R想学更多,希望以后能阅读到更多关于R方面的只是