SVM
支持向量机(support vector machine),简称SVM,是一种基于监督的二类分类模型。 通俗的说,SVM是通过选取高维空间上的一个超平面(hyperplane)来进行数据分类,这个超平面即为分类平面,构成这个超平面的向量,即为支撑向量。SVM先已广泛应用于统计分析,回归分析和机器学习中。
One class SVM
与传统SVM不同的是,one class SVM是一种非监督的算法。它是指在训练集中只有一类positive(或者negative)的数据, 而没有另外的一类。 而这时,需要学习(learn)的就是边界(boundary),而不是最大间隔(maximum margin)。
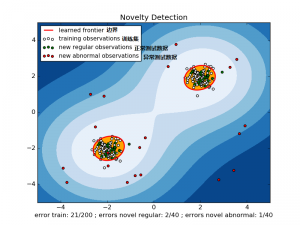
如下图中所示,
白点:训练集
红线:边界
绿点:正常测试数据
红点:异常的测试数据
核函数(Kernel)
在e1071库中的One class SVM采用的是径向基函数(RBF)中的高斯核方程。
高斯核的表达式为 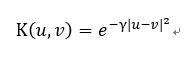
也有人把表达式写成
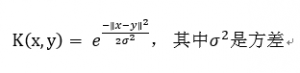
应用实例 — 新奇检测Novelty detection
R 代码实例
library(e1071)
data(iris)
iris$SpeciesClass[iris$Species==”versicolor”] <- “TRUE”
iris$SpeciesClass[iris$Species!=”versicolor”] <- “FALSE”
trainPositive<-subset(iris,SpeciesClass==”TRUE”)
testNegative<-subset(iris,SpeciesClass==”FALSE”)
# 60% 的 “TRUE” 数据为训练集
inTrain<-createDataPartition(1:nrow(trainPositive),p=0.6,list=FALSE)
trainPredictors<-trainPositive[inTrain,1:4]trainLabels<-trainPositive[inTrain,6]
# 40%的”TRUE”数据和所有”FLASE”数据为测试集
testPositive<-trainPositive[-inTrain,]
testPosNeg<-rbind(testPositive,testNegative)
testPredictors<-testPosNeg[,1:4]
testLabels<-testPosNeg[,6]
# 建模
svm.model<-svm(trainPredictors,y=NULL,
type=’one-classification’,
nu=0.10,
scale=TRUE,
kernel=”radial”)
# 预测训练集和侧视集
svm.predtrain<-predict(svm.model,trainPredictors)
svm.predtest<-predict(svm.model,testPredictors)
confTrain<-table(Predicted=svm.predtrain,Reference=trainLabels)
confTest<-table(Predicted=svm.predtest,Reference=testLabels)
运行结果:
测试集结果矩阵
confusionMatrix(confTest,positive=’TRUE’)
confusionMatrix(confTest,positive=’TRUE’)
Confusion Matrix and Statistics
Reference
Predicted FALSE TRUE
FALSE 98 7
TRUE 2 11
Accuracy : 0.9237
95% CI : (0.8601, 0.9645)
No Information Rate : 0.8475
P-Value [Acc > NIR] : 0.01008
Kappa : 0.6671
Mcnemar’s Test P-Value : 0.18242
Sensitivity : 0.61111
Specificity : 0.98000
Pos Pred Value : 0.84615
Neg Pred Value : 0.93333
Prevalence : 0.15254
Detection Rate : 0.09322
Detection Prevalence : 0.11017
Balanced Accuracy : 0.79556
‘Positive’ Class : TRUE
我们可以从运行结果中看到,预测的准确率为92.37%, 在混淆矩阵中,一共有9(2+7)个数据被错分。
应用模型到训练数据集中
print(confTrain)> print(confTrain) ReferencePredicted TRUE FALSE 6TRUE 26
小结及延伸
SVM作为监督算法一直在工业界倍受欢迎,有着广泛的应用。本文中提及的非监督one class SVM算法也同样受到重用着,例如,Oracle的自家数据挖掘中,特指Oracle 11g/12c中的ODM(Oracle Data Mining),就是使用one class SVM来进行异常检测, Oracle给它起了个名字,叫anomaly detection。
刚在自己数据上试了一下,结果如下:这种结果可以接受么?
还有,此方法的适应场景是什么?是针对正负样本严重失衡的情景么?