作者 pauke
3 线性模型
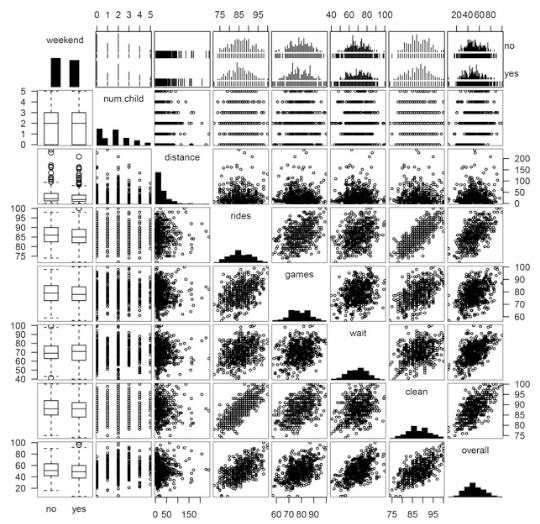
3.1 建模探索:gpairs, scatterplotMatrix
gpairs和scatterplotMatrix在数据探索方面各有长短,gpair能够很好地应对因子变量,scatterplotMatrix 则有一个不错的出图效果。
scatterplotMatrix结果:
-线性模型.png)
gpairs 结果:
corrplot.mixed结果:

3.2 模型建立
Call:
lm(formula = overall ~ rides + games + wait + clean, data = amu)
Residuals:
Min 1Q Median 3Q Max
-29.944 -6.841 1.072 7.167 28.618
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -131.40919 8.33377 -15.768 < 2e-16 ***
rides 0.52908 0.14207 3.724 0.000219 ***
games 0.15334 0.06908 2.220 0.026903 *
wait 0.55333 0.04781 11.573 < 2e-16 ***
clean 0.98421 0.15987 6.156 1.54e-09 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 10.59 on 495 degrees of freedom
Multiple R-squared: 0.5586, Adjusted R-squared: 0.5551
F-statistic: 156.6 on 4 and 495 DF, p-value: < 2.2e-16
#置信区间
2.5 % 97.5 %
(Intercept) -147.78311147 -115.0352764
rides 0.24993998 0.8082161
games 0.01760038 0.2890718
wait 0.45938535 0.6472675
clean 0.67011082 1.2983144summary信息解读:
残差(residual)表示数据和最佳拟合线之间的吻合程度。lm1的结果显示,这个模型离实际情况差很远(-30 <=残差<= 30为可采纳),残差的中位值在0附件可表示残差对称。
参数估计(Coefficients):模拟系数估计(Estimate),模拟系数不确定性(Std.Error),t value,Pr(>|t|)和显著性标识可表示该系数是否显著非零,也可用来计算置信区间,例如rides系数置信区间为:1.7033 ± 1.96 × 0.1055 = (1.495,1.910)。系数置信区间也可用 confint(lm1)获得。
接着是总体拟合程度:标准化残差(Residual standard error); R方,该统计量衡量模型捕获的因变量方差,反映该模型可以解释响应变量变化值,本案例的模型不是很好,仅能解释5%左右的loss值变化。
最后是F估值(F-statistic):用于检验与单纯使用均值来预测相比,该模型是否能够更好预测。本案例p值<=0.05,说明有存在价值。

其他summary结果:
Call:
lm(formula = overall ~ rides + games + wait + clean + +weekend +
logdis + num.child, data = amu.std)
Residuals:
Min 1Q Median 3Q Max
-1.51427 -0.40271 0.01142 0.41613 1.69000
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.37271 0.04653 -8.009 8.41e-15 ***
rides 0.21288 0.04197 5.073 5.57e-07 ***
games 0.07066 0.03026 2.335 0.0199 *
wait 0.38138 0.02777 13.734 < 2e-16 ***
clean 0.29690 0.04415 6.725 4.89e-11 ***
weekendyes -0.04589 0.05141 -0.893 0.3725
logdis 0.06470 0.02572 2.516 0.0122 *
num.child 0.22717 0.01711 13.274 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.5709 on 492 degrees of freedom
Multiple R-squared: 0.6786, Adjusted R-squared: 0.674
F-statistic: 148.4 on 7 and 492 DF, p-value: < 2.2e-16
Call:
lm(formula = overall ~ rides + games + wait + clean + +weekend +
logdis + num.child.f, data = amu.std)
Residuals:
Min 1Q Median 3Q Max
-1.25923 -0.35048 -0.00154 0.31400 1.52690
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.69100 0.04488 -15.396 < 2e-16 ***
rides 0.22313 0.03541 6.301 6.61e-10 ***
games 0.04258 0.02551 1.669 0.0958 .
wait 0.38472 0.02338 16.453 < 2e-16 ***
clean 0.30917 0.03722 8.308 9.72e-16 ***
weekendyes -0.02227 0.04322 -0.515 0.6065
logdis 0.03187 0.02172 1.467 0.1429
num.child.f1 1.01610 0.07130 14.250 < 2e-16 ***
num.child.f2 1.03732 0.05640 18.393 < 2e-16 ***
num.child.f3 0.98000 0.07022 13.955 < 2e-16 ***
num.child.f4 0.93154 0.08032 11.598 < 2e-16 ***
num.child.f5 1.00193 0.10369 9.663 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.4795 on 488 degrees of freedom
Multiple R-squared: 0.7751, Adjusted R-squared: 0.77
F-statistic: 152.9 on 11 and 488 DF, p-value: < 2.2e-16
Call:
lm(formula = overall ~ rides + games + wait + clean + logdis +
child.or.not, data = amu.std)
Residuals:
Min 1Q Median 3Q Max
-1.23491 -0.35539 -0.00838 0.32435 1.46624
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.70195 0.03906 -17.969 < 2e-16 ***
rides 0.22272 0.03512 6.342 5.12e-10 ***
games 0.04424 0.02539 1.742 0.0821 .
wait 0.38582 0.02326 16.589 < 2e-16 ***
clean 0.30876 0.03696 8.354 6.75e-16 ***
logdis 0.03512 0.02148 1.635 0.1027
child.or.notTRUE 1.00565 0.04683 21.472 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.4782 on 493 degrees of freedom
Multiple R-squared: 0.7741, Adjusted R-squared: 0.7713
F-statistic: 281.5 on 6 and 493 DF, p-value: < 2.2e-163.3 线性模型流程总结
1, 数据清洁和规整程度检查;
2,数据分布情况检查,保证各个变量之间的关系适合建模;遇到分布不正,或者数据类型不同的,要考虑进行变换,如本案例中对 distance进行的log转换。
3,检查二维散点图和相关图,确定自变量间是否存在共线问题(相关系数r > 0.9)。若是存在相关,则是处理线性模型共线性的问题,即a、视变量价值决定变量去留;b、提取主成分因子来去除相关性;c、使用对共线性有抗性的方法,如randomforest。
4,确保数据尺度上一致,可使用scale来进行数据变量的标准化。
5,建立模型,并输出残差分位图展示对观测的拟合情况;通过plot(model)绘制模型结果,从而进一步判断模型的可行性和数据关系的非线性,同时识别离群点。
6, 通过调整模型的解释变量,来比较其解释性和拟合程度:R2、残差分布和anova()来比较。
7,报告参数的置信区间和模型结果解释。