来自 http://www.dxy.cn/bbs/topic/25716050?onlyHost=1
这是Google利用其用户的搜索记录来预测流感发病率的模型及验证。
从方法来说很简单,但是肯定也尝试了一些方法/模型以后决定了这是最合适的模型之一。
我暂时忽略这里最后所描述的一些具体的方法和程序,一部分细节只有在重新做一遍的时候才会有体会。
背景:
美国CDC每一周会发布关于“流感症状”患者就诊数据,起起伏伏就说明流感的发生多少情况。这个数据包括全国统计和每个州自己的统计。
这个数据在当时是延迟大约1-2周发布的。可能是统计的需要。
当时已经有不少其他来源的数据在尝试和这个数据做相关性分析,比如OTC相关药物的销售情况等。
研究目的:
考虑到Google的搜索的数据极大,可能能找出一些和流感多少相关的因素。这个研究就是企图去利用google搜索数据来寻找和流感的相关关系,并且“预测”流感的发病率。这里要注意的是,这并不是一个纯正的预测,而是预测上面说的“流感症状”患者就诊数据。因为它的发布是有1-2周延迟的,所以只要比这个数据早发布,就是在预测这个数据,而不是预测流感。
关于这点的一些讨论:
- 如果CDC自己发布的数据能更加及时点,比如周一就能公布上周的数据,那么这个预测估计就没啥用。
- 这个要去预测的数据 – “流感症状”就诊数据本身就非常适合做这类的预测。从推断的角度说,相关的搜索比较可能是用户搜索和流感的相关症状或者治疗,并不一定完全指向“实验室验证”的流感,而更加和流感症状相关。(当然这只是推测)
方法:
- 这个方法对我来说还是比较新的:
- 确定要预测的是: “流感症状”就诊数据; 确定我们有什么:用户搜索数据,可以区分其来源,也就是说可以按照不同的州 State来区分其。
- 模型:logit(P) = β0 + β1 × logit(Q) + ε 这是Logit是Binary模型中最常见和基本的一种。这个的P用的不是“流感症状”就诊数据的绝对值,而是比例,我估计是占所有就诊量的比例。
- 决定Q是什么:这是这个模型最关键的地方,这里的关键是,先不管什么流感不流感,找出在美国google上搜索的最多的5000万个关键词 – 5000万个!基本应该囊括很多了吧。。我们得到的是每一个关键词被搜索次数的一个时间序列(time series)。然后一个个的,对,一个个的带入上面的模型,每一个关键词都会生成一个“模型“,然后就看着一个个的回归的模拟程度高不高,列出最高的100个关键词,进入下一步。
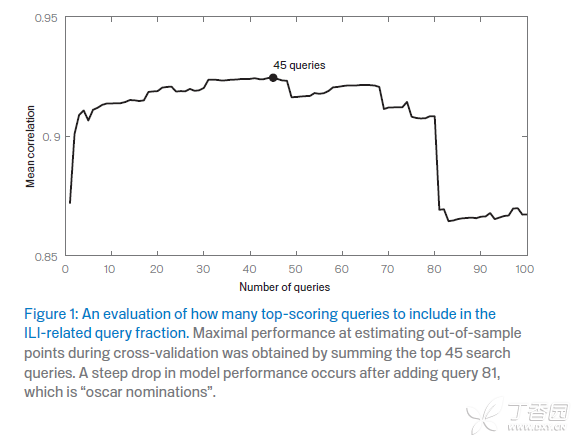
- 选择到底要用几个关键词的搜索数量来做预测:我们已经得到了,单个词预测性最好的100个词,然后的做法就是用排名第一的词放到模型里,得出LOGIT(P‘),然后和真实的LOGIT(P)去做相关性分析,相关性越高说明模拟的程度越好。然后把排名第一加第二的词加起来作为Q,一样去看其结果和真实数据的相关性,以此类推到前100个词加起来作为Q的结果。最后得出的结果Plot如下:
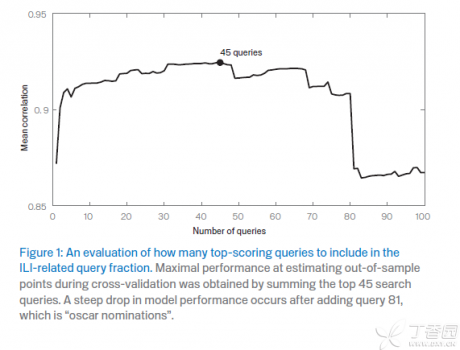
从这个结果得出,前45个词加起来作为Q的模型的模拟度最好,最接近真实数据。所以就确定了这个预测模型的具体自变量:这45个词的搜索量叠加作为Q。
- 上面的一步的图有一个定性的解释,也就是前45个词中间,每增加一个词,对于最后需要预测的结果都是有正面的意义,增加的是有用的信息,而从第46个词以后出现的词,增加的更多的是噪声,也就是说在长期来说,并不能帮助解释最终的结果,而这里出现在前100位,可能只是因为我们选取的时间段内,这些搜索只是恰巧和我们要预测的结果同时出现。
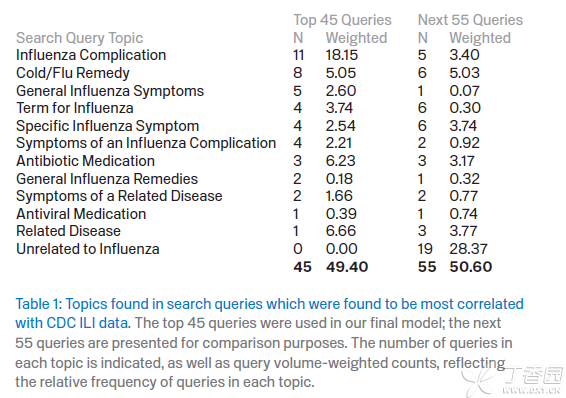
看一下另外一个相关的表:
从这里可以看出,前45个词全部都和流感相关,而后面的55个中则有19个和流感无关,其中也包括了”高中篮球”, 这也一定程度上印证了上面的定性解释。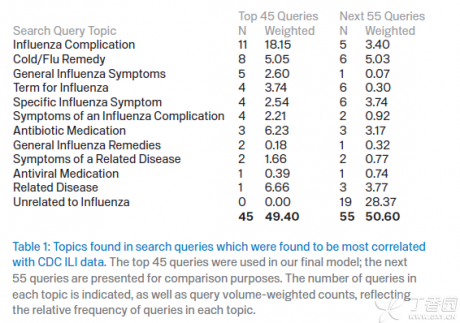
- 内部验证(Internal Validation): 用上面得到的模型,去推算03-07年的P值,和真实的P做对比,发现相关系数达0.90(全国数据)。而在07-08年的数据去做一个个州分开的预测对比,相关性达0.97.
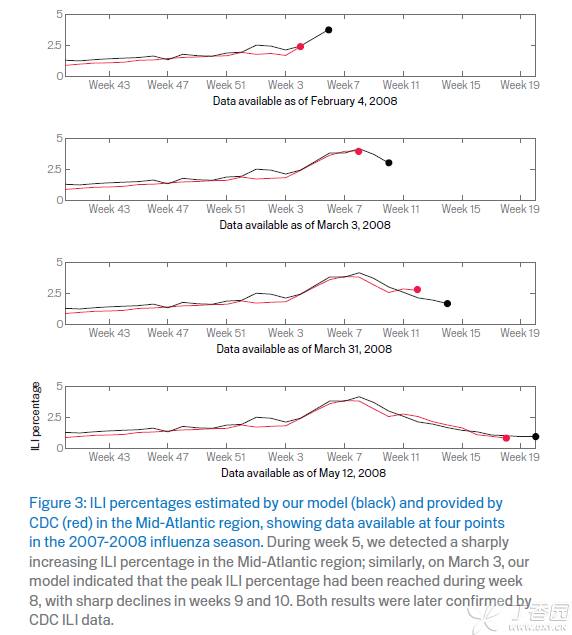
- ”未来“验证:用这个模型去预测未来的数据。我们得到模型的时候是08年初,为了更好的说明这个模型是有用的,就在08年初开始,用google 搜索数据去得到推算出来的P,然后和1-2周后公布的实际的P去做比较,来看这个模型是否好:最后的结果是相关性达0.90.
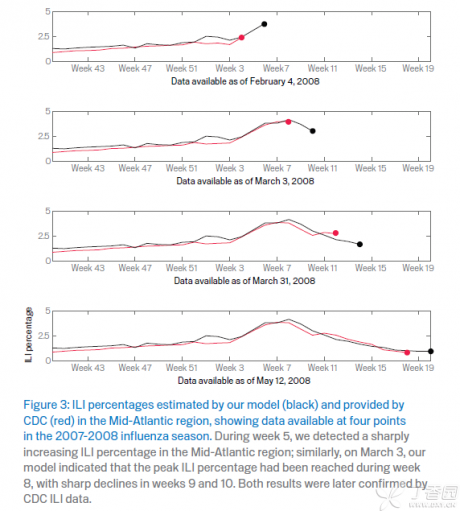
结论和讨论:
- 这个模型无疑是一个很快而且比较准的预测”流感症状”接诊数据。比官方数据快1-2周则意味了有更多的时间来准备如何应对可能爆发的流感。
- 从上图可以看出,这个模型的预测似乎Sensitivity比较高,但是Specificity相对低一些,也就是说有一些预测的高,实际不一定高,但是实际会高的时候,大多数都能被预测到。 预测“假高”可能由其他的一些因素引发,例如和流感相关药物的安全性新闻,或者被召回,则可能让用户增加对相关词汇的搜索量,但并比一定是因为流感的增加。
- 有一个文章没说到的可能的情况:Amplification, 也就是说如果这个预测数据被广泛应用,当预测说会增加的时候,市民可能会对流感相关症状的敏感性增加,也增加了其自我怀疑和去医院就诊的可能性。下一个阶段的真实P和预测的P都将会更增加。也就是说P值以及预测的P值的volitility可能会增加。这个的前提是,这个预测数据被市民广泛采用。我的这个假设源于”Lucas Critique”( http://www.douban.com/note/217511128/::__IHACKLOG_REMOTE_IMAGE_AUTODOWN_BLOCK__::3 ) 核心并不是不能做预测,而是一旦根据历史数据所形成的可以操作的,可以被认知的法规/方法被公众所知晓,这本身就影响了公众的期望,而使得公众的行为发生改变。那么根据历史数据所做的工作在未来将不是一样的有效。
- 个人觉得这个研究所是用的整个方法是非常精彩的,很简单但是有效。我相信研究人员是尝试了非常多的方法,最后得到这个的。
小编:
虽然这个项目的结果后来被证明并不稳定,但是其在大数据领域的代表性意义是不可替代的,有兴趣的同学也可以看看他人分析该项目失败原因的几篇文章:
从谷歌流感趋势(GFT)出错看大数据发展之路
数据并非越大越好:谷歌流感趋势错在哪儿了?