什么是桑基图
在给出定义之前,先看下几个著名的Sankey图实例

这个是来表示拿破仑进攻俄国过程时,队伍人员的变动情况。棕色表示进攻、黑色表示撤退。从这个图片上可以清晰的看出在各个阶段的人员战斗减员情况。
Sankey图的种类
按照节点之间的相互流向关系,可以分成单层Sankey和多层Sankey(multiple level Sankey diagram)。
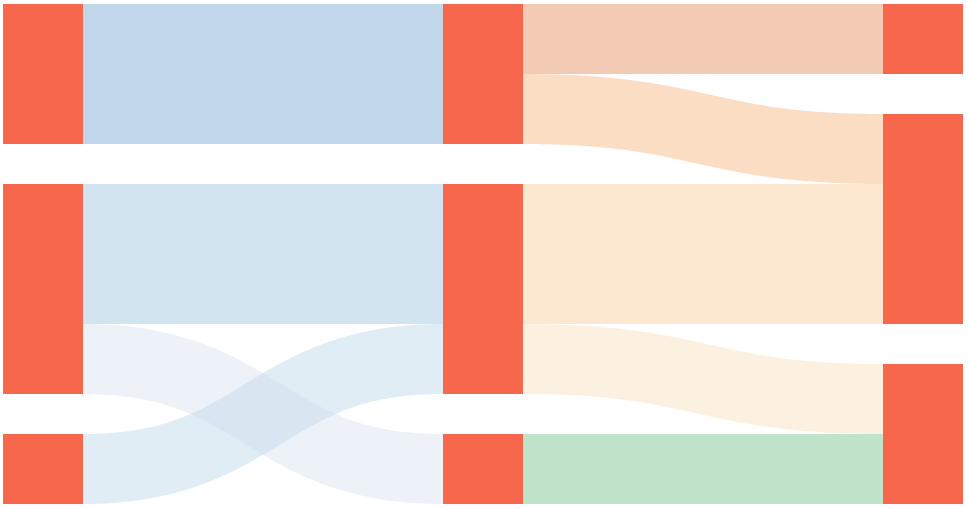
上图的左半边和右半边都是一个单层桑基图,合在一起就是一个多层桑基图。
不过这个图还是很容易读懂的,没有出现跨层次之间的数据流动。而后面绘制的能源使用图则出现节点层次不规则导致的图片较为混乱的情况。
使用Power BI绘制
添加可视化模型
在官方自带的可视化模型中并不包含Sankey图,不过可以使用第三方提供的资源。在商店(store)上搜索Sankey,即可找到这个可视化模型,加载到当前文件中即可。
整理数据
数据和可视化模型是一个相互选择的过程,在参考文档中提供了欧洲不同类型能源的使用数据。在这里我们需要搞清楚如何将数据整理成可视化模型能够识别/使用的形式。
在Sankey可视化模型中需要填写几个参数:
- Source 输入源ID
- Destination 输出源ID(也包含中间节点)
- Weight 从输入到输出节点之间的权重
- Destination Label 输出节点的名称
- Source Label 输入节点的名称
所以所谓的整理过程就包含了如下过程:
- 节点的汇总
- 节点之间的权重
在Power BI中建立如下数据关系:
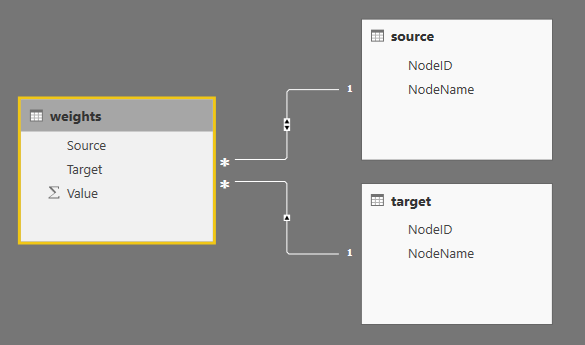
其实source和target是相同的数据表,只不过我们需要将weight表中的Source、Target字段都关联上名称,两个表之间不同同时进来多个数据关系,所以需要也建立一个target表。
还有一种解决方法是,抛弃ID的设计,直接使用名称来替代ID,这样只需要上图中的weight表就可以了。
得到结果

经过上述过程,就得到了如上能量的形式转换以及使用流向图。
图片特别的杂乱?
不过这个可视化图形看起来是异常的复杂,这也是没有办法的事情,因为这里能量的利用方式种类过多,而且会出现原始能源、转化后能源会同时经过某个节点,这样也就导致了整个图形看起来特别的没有层次感。不过客观上,这是由于数据节点的属性划分上没有考虑清楚所导致的。
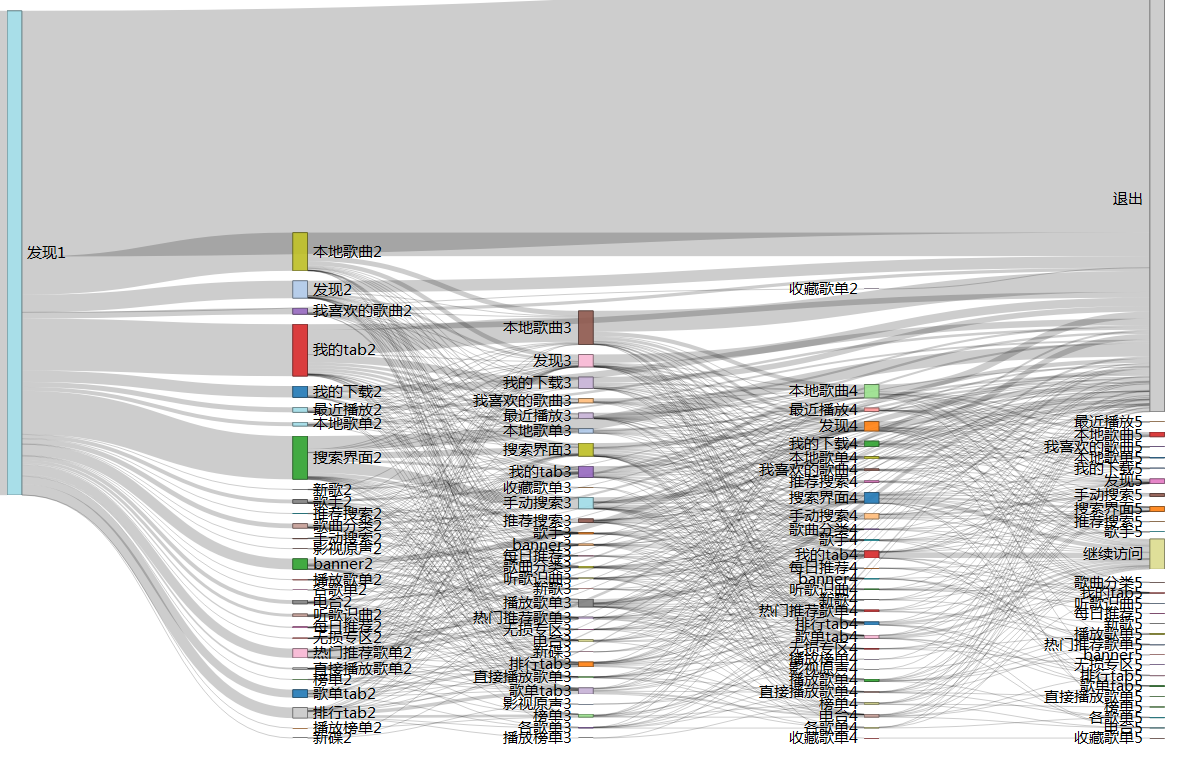
上面是自己绘制的一个音乐应用的页面流量变化图,这个图片就比较直观(虽然第一眼感官上可能更杂乱),因为从前到后中间流量数据是守恒的。整个图形分成了四个层次,每次跳转的时候都会有部分的点击数据流失掉。
Sankey模型文件
想直接操作创建好的模型,可以下载随后的pbix文件。欧洲能源Sankey图.pbix
使用Python绘制
在数据科学中,python基本上提供了全链路的解决方案。如果能在Python环境中绘制出来,自然可以减少易一些不必要的工具转换而带来的数据整理等过程摩擦。例如可以直接在jupyter notebook中完成数据采集、整理、清洗和可视化,以及后续的建模等。而python的绘图生态中也有这样的工具支持绘制Sankey图。
使用matplotlib绘制
1 2 3 4 5 6 7 |
from matplotlib.sankey import Sankey sankey = Sankey() sankey.add() # 1 #... sankey.add() # n sankey.finish() |
使用matplotlib绘制的范式如上,就是在不断的添加各种素材来绘制分叉等图片结构。
1 2 3 4 |
sankey.add(flows=[1, -1, 0.5], orientations=[0, 0, 1], labels=['input', 'output', 'third flow (input)'], rotation=-90) |
例如上面的代码即可绘制出来如下图形:
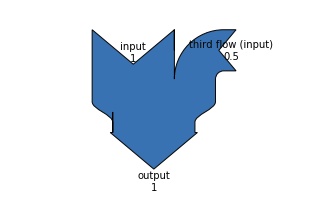
通过这个图形可以看出,使用matplotlib绘制起来虽然简单,但是可视化的效果比较差。简单来说就是丑拒。
使用plotly模块绘制
plotly作为一个完成的数据可视化解决方案,有着自己的使用程序和模式,Python数据可视化:顶级绘图库plotly 这篇文章通俗简明的介绍了使用关键过程。
下面内容是着手使用这个plot.ly来绘制一个Sankey图。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import plotly.plotly as py import plotly plotly.offline.init_notebook_mode(connected=True) # 在jupyter book中使用 data = dict( type='sankey', node = dict( label = ["原料1", "原料2", "中间产物1", "中间产物2", "成果", "损耗"], color = ["blue", "blue", "green", "green", "black", "red"] ), link = dict( source = [0,1,0,2,3,3,2], target = [2,3,3,4,4,5,5], value = [8,4,2,6,4,2,2] )) layout = dict(title = "原料转化路径图") fig = dict(data=[data],layout=layout) # 注意这里的data被转化为数据,可以支持同时绘制多个图形 plotly.offline.iplot(fig, validate=False) |
得到的结果如图所示:
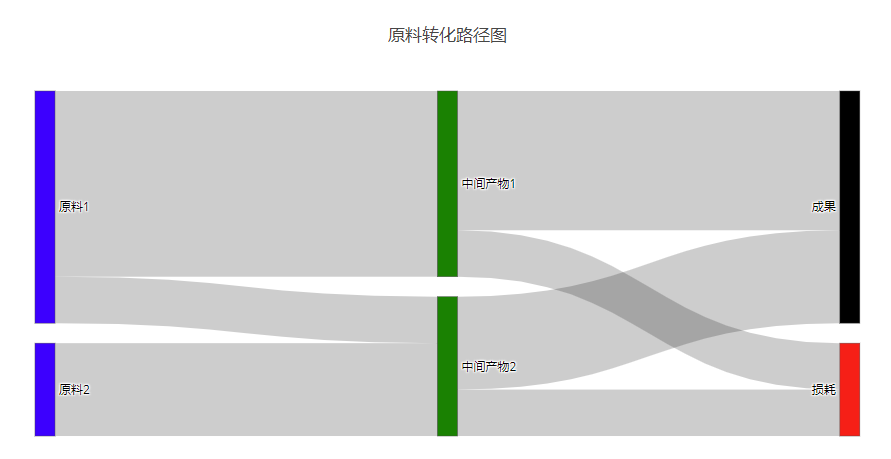
在使用plotly绘制桑基图的时候最关键的步骤就是准备数据,其中最关键的就是node和link:
- node :各个节点的名称以及颜色;
- link :通过source、target以及value来决定各个流量的转化
而layout数据则规定了整个图形的一些数据,例如图表的title等。
小结
从实现的可视化目标看,桑基图和行为漏斗很相似,往往是用来展示在事物进行过程中,在各个阶段的转化效率。而漏斗图的往往是需要提取在这个过程的单一路径,而桑基图则可以同时展示多个路径的转化过程,图形自然也复杂许多。
如果你的数据和指标可以使用漏斗来展示,最优先的方式也还是漏斗模型; 甚至不是很复杂的桑基图都可以通过多个漏斗模型来解决,毕竟漏斗是线性的,符合人类的思考模式。
参考文档
Sankey Diagram in Python 需要再使用一个绘图库plotly,注意plotly有online和offline两种绘图模式,而且搭配notebook使用online模式时还需要配置额外的连接信息。
Getting Started with Plotly for Python
A tutorial about drawing Sankey graphics using matplotlib 需要一步步的添线条,而且可视化结果很丑,虽然效果一目了然。好处就是直接使用matplotlib就可以绘制了
Sankey Diagram with google charts 利用google charts这个js可视化工具来绘制,不过中间会使用到对应的数据格式,毕竟是js生态下的绘图工具,学习成本会高一些。
Working with the Python API Data will actually contain all the traces ,A trace is just the name we give a collection of data and the specifications of which we want that data plotted.