[目录]
- 第一章:概述
- 第二章:整体数据分层
- 第三章:整体实现框架
- 第四章:元数据
- 第五章:ETL
- 第六章:数据校验
- 第七章:数据标准化
- 第八章:去重
- 第九章:增量/全量
- 第十章:拉链处理
- 第十一章:分布式处理增量
- 第十二章:列式存储
- 第十三章:逻辑数据模型(数仓模型)
- 第十四章:数据模型参考
- 第十五章:维模型
- 第十六章:渐变维
- 第十七章:数据回滚
- 第十八章:关于报表
- 第十九章:数据挖掘
数据仓库实践杂谈(三)整体实现框架
从获取数据到最后呈现结果的整个过程,称为数据处理过程,一般简称ETL(Extract-Transform-Load,即提取、转换和加载)。但实际上,可能会转换很多次,也会加载很多次。
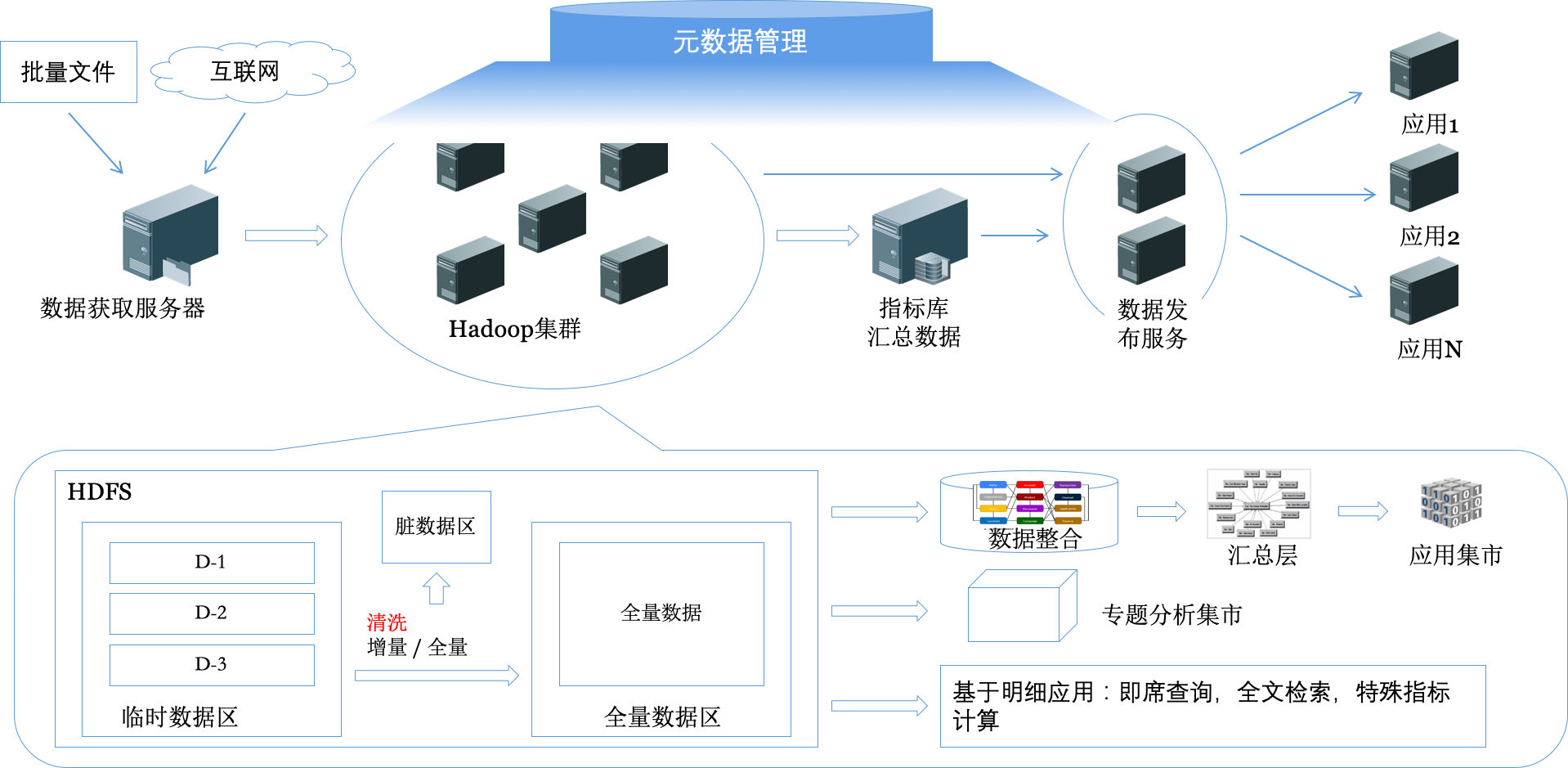
下图是一个基于大数据的完整的数据处理架构与流程。很简单的图,能看出整体的架构和处理流程。先记住整个过程都应该在“元数据”的管理和控制之下进行。
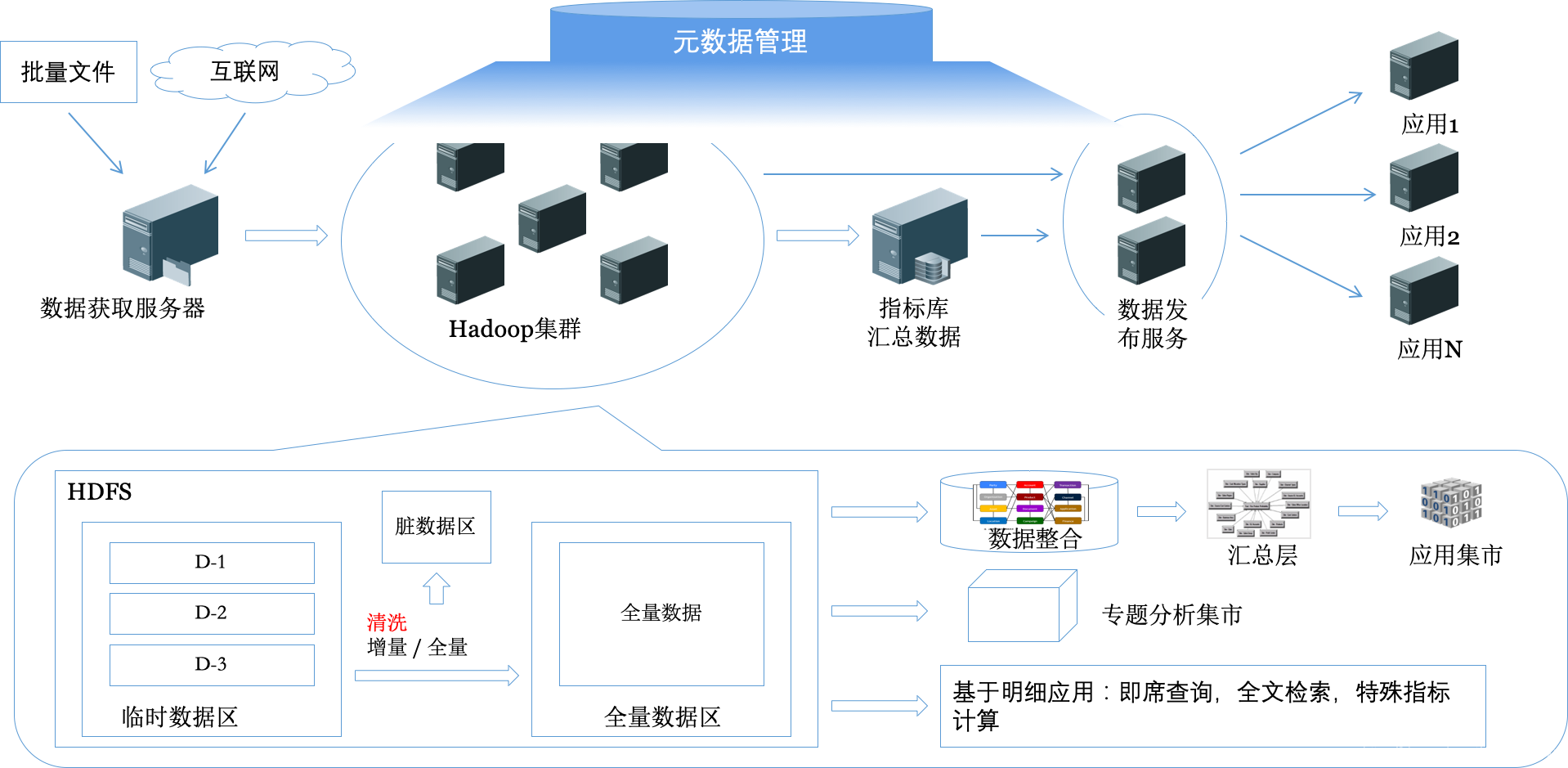
- 数据抓取
传统模式一般通过FTP(对方传来,或者去对方服务器抓取),HTTP下载,甚至有对方开放数据库直接去卸出的。总之,目的就是为了得到数据源系统每天产生的数据文件。一般情况都是文本文件。文件抓取过来之后应在文件服务器原封不动地保存,一般保存3-7日。 - 数据预装载
根据处理实现技术的不同,预装载的定义有所区别,但总体而言就是把数据从文件服务器上拿到可以进行数据处理的服务器环境中,比如装载到数据清洗的执行服务器上,或者加载到HDFS中。 - 数据校验清洗
最常规的做法就是把每个数据文件都打开,从头到尾逐行读取,然后逐个字段进行校验,把不合规格的数据筛选出来,放到脏数据区,没问题的数据加载到全量数据区。这是一个很复杂的过程。涉及到元数据、数据校验、增量/全量处理等概念。有时候数据清洗还会涉及到一个“去重”的问题,就是来的数据可能有重复的,需要剔除。同时往往需要一次性处理的数据很多,需要考虑处理效率和存储的方式。 - 建立数仓模型
诚然,并不是所有的平台都会建立数仓模型,也不是所有的数仓模型都发挥了应有作用。准确说,能很好发挥作用的数仓模型不多。但不管如何,要树立一个正确的概念,数仓模型是为了统一、一致化地反映全局业务现实,并不是某一个单一目标(比如业务统计)。数仓模型是高度范式化的,而且不丢失数据细节的。数仓模型的基础是三范式(Third Normal Form,3NF)的实体关系模型。模型一般参考Teradata和IBM的逻辑数据模型。 - 建立统一汇总层
汇总层,顾名思义,就是专门为了汇总,也就是数据统计而建立的模型。虽然数据统计并不是数据分析的全部,但确实是最重要的。任何企业的经营管理指标,金融企业的监管报送指标,都需要统计。统计就需要考虑指标(如营业额)和维度(按地区、时间、品类统计等)。
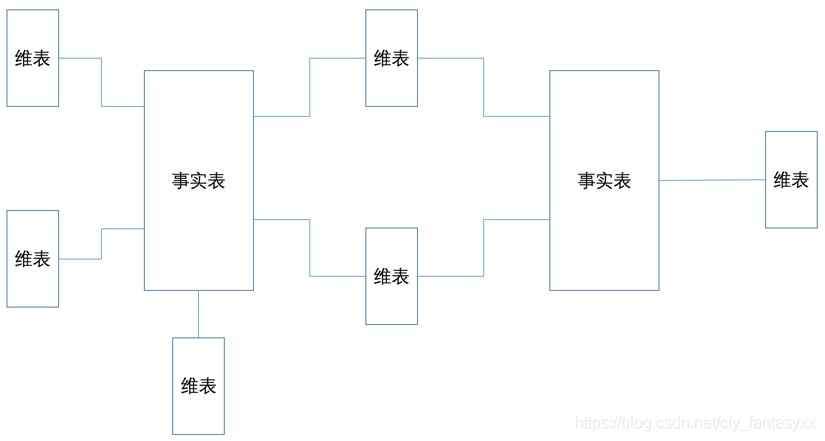
为何叫统一汇总呢,就是在一个企业里需要统计的指标会有很多,不同的指标需要关联不同的统计维度,但很多维度其实会被复用(共享维),所以这里的核心工作就就是定义指标和共享维,形成一个星系形状的模型。 - 建立分析集市
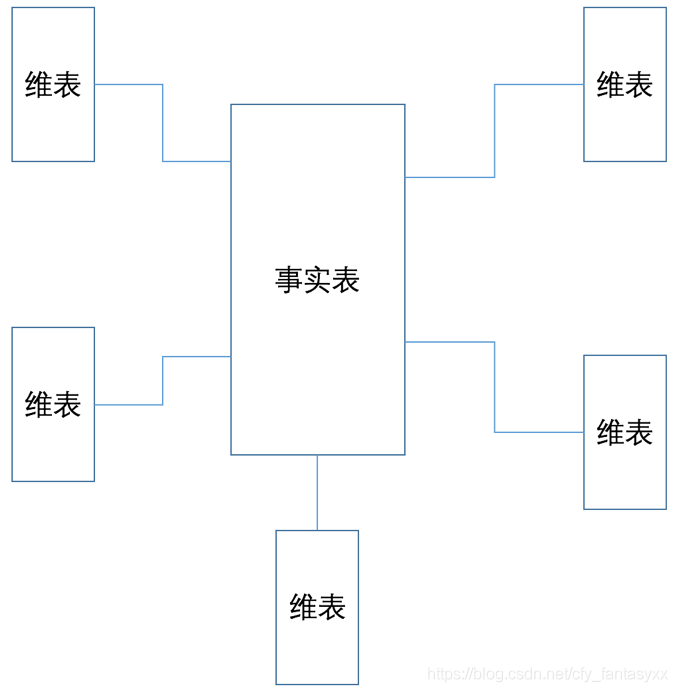
分析集市可以看作为是汇总层的一个子集。从星系中抽取一个独立的业务主体,形成星型模型。看图,确实像个星星,很形象。
至于早年有个争论的雪花模型,就不讨论了,没价值。分析集市,也称为Cube(立方体),如果考虑三个维度的情况,就很形象了;实际上这个立方体是多维的。这个Cube的特点就是,可以指定任何的维度进行汇总。而且从效率的角度,可以事先把所有层次都汇总好了,直接拿结果就好。有三种类型:ROLAP(基于关系数据库)、MOLAP(基于多维组织)、HOLAP(两者混合)。ROLAP著名的开源Mondrian/JPivot也不维护了——虽然我很喜欢他使用的MDX语言(微软提出的)。Cognos应该是这方面最成功的商业软件了——被IBM收购之后也没怎么用过了。开源的有基于Hadoop的Kylin(不是那个操作系统,而是Apache Kylin),eBay开发,贡献给了Apache基金会。写这么多工具,主要就是一句话,针对Cube的查询别想自己实现了,选个合适的工具,虽然可选的工具也不多。
对数据的应用千花百样,并不是所有的平台都需要遵循上述过程从头到尾都要做的。对于很多机构而言,只要把全量明细数据管理好、用好,就能满足需求。数仓模型是否真的有价值,其实争论就没停过。把业务简化一下,如果一个企业的数据来源仅有一个业务系统,则基本上不需要整合。业务系统的模型就能充分反映自身的业务,那整合什么呢?直接从贴源明细做报表,计算特定指标,生成分析集市,也是一个多快好省的办法。
最后强调的是上面谈到的基本都是技术手段,但要真正让系统运作好,使用好数据仓库,就需要从根本上把数据当做资产。管理数字资产,首先要做好的是数据治理和数据标准化。在这个基础上,配合上面所谈的流程和技术,才能把数据仓库玩转。
未完待续。
————————————————
版权声明:本文为CSDN博主「cfy_fantasyxx」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cfy_fantasyxx/article/details/102888086